VIAGGIO NEL DNA DELLE ORGANIZZAZIONI
Ontologia cenni(r)

![]()
![]()
![]()
|
VIAGGIO NEL DNA DELLE ORGANIZZAZIONI Ontologia cenni(r)
|
|
|
L'ontologia. L’ontologia , “lo studio dell’essere in quanto tale” secondo Aristotele, è concepita usualmente come una disciplina strettamente filosofica, lontana dal mondo della tecnologia. Negli ultimi anni, l’esplosione delle comunicazioni in rete ha favorito lo sviluppo di un fenomeno che sarebbe stato difficile immaginare: gli aspetti ontologici dell’informazione acquistano un valore strategico. Tali aspetti, infatti, sono indipendenti dalle forme di codifica date all’informazione che può essere isolata, recuperata, organizzata, integrata in base a ciò che più conta: il suo contenuto. Le esigenze e i problemi che l’utilizzo delle ontologie consente di risolvere non sono pochi:
Anche nelle Organizzazioni, che adottano un approccio semplice alla gestione della conoscenza, si pone il problema di individuare uno strumento che consenta la modellazione e la strutturazione del knowledge (documenti di testo, slides, pagine Web, …) condiviso da gruppi di persone. Attraverso la definizione di ontologie è possibile eliminare la confusione terminologica e concettuale ed individuare entità alle quali un pacchetto di conoscenza fa riferimento. Inoltre, è possibile organizzare e rendere esplicito il significato referenziale in modo da poter comprendere l’informazione. Condividere e comprendere la conoscenza facilita il suo riutilizzo tra agenti e contesti diversi. Una prospettiva applicativa delle ontologie riguarda le iniziative di standardizzazione del contenuto di informazioni su Web. Oggi, infatti, uno dei problemi più comuni che i navigatori del Web devono affrontare è la ricerca di informazioni in maniera accurata. Con il crescere delle pagine pubblicate, i classici motori di ricerca cominciano a diventare sempre meno idonei nella ricerca delle informazioni. Questi classificano le informazioni contenute in una pagina basandosi sulle parole presenti in essa. Così se si intende cercare informazioni su un determinato argomento, ad esempio sulla coltivazione dei “girasoli”, si potranno ottenere, come risultato della ricerca, una serie di pagine che hanno a che fare con la vendita diretta di semi di girasole, pagine pubblicitarie su una determinata marca di olio di girasole, l’home page del signor “Girasoli” o quella dell’hotel “Soli e Girasoli”, e così via. Quindi la presenza del termine oggetto della ricerca nella pagina Web fa sì che questa sia candidata ad essere proposta a chi effettui la ricerca. Per consentire una ricerca più accurata occorrerebbe classificare le pagine Web ricorrendo a descrizioni delle pagine stesse, tramite quelli che, tecnicamente, vengono chiamati metadati. Quanto appena descritto costituisce quello che viene indicato come Web semantico. Per ordinare la conoscenza presente sulle pagine e, in generale, nei domini o contesti che si intendono descrivere e rappresentare in modo formale, si ricorre alle ontologie. In letteratura un’ontologia è definita come un’esplicitazione formale di concetti relativi ad un certo dominio di interesse (detti classi o semplicemente concetti), delle proprietà di ogni concetto che descrivono le caratteristiche e gli attributi del concetto (slot detti anche roles o properties) e dei vincoli, limitazioni sugli slot (facets o role restrictions). Quindi un’ontologia è una descrizione formale di un dominio di conoscenza. Il risultato di un'ontologia è una descrizione strutturata gerarchicamente dei concetti importanti e delle loro proprietà che trovi il consenso di diversi attori interessati a condividerla e utilizzarla. Le fasi metodologiche necessarie allo sviluppo di un’ontologia possono essere così riassunte:
L’obiettivo di tale fase è quello di produrre un’ontologia sulla base delle specifiche date nella fase precedente. Si possono individuare tre step nella fase di raffinamento:
Gli elementi di un’ontologia sono organizzati, generalmente, in tassonomie nelle quali si identificano le relazioni “is_a” e “part_of”. Le prime permettono di identificare tutte le classi (descrivono in senso lato i concetti che si vogliono rappresentare) e le sottoclassi che saranno utilizzate nella rete semantica; le seconde, invece, consentono l’identificazione delle relazioni esistenti tra le diverse sottoclassi. La tassonomia ottenuta permette di dare una struttura all’ontologia. Dopo aver chiarito il concetto di ontologia e il suo processo di sviluppo, è necessario fare una piccola osservazione. Deve essere sottolineato il fatto che, oramai, numerose sono le ontologie sviluppate in ambito organizzativo per la formalizzazione dei flussi di informazioni all’interno di qualsiasi impresa. Gli strumenti di sviluppo presenti sul mercato sono diversi e offrono ambienti dove definire gli elementi che formeranno l’ontologia, i loro attributi e le loro relazioni (ad esempio Protégé). Accanto agli ambienti di sviluppo vengono offerti, inoltre, diversi modelli per lo sviluppo di “enterprise ontology”. Tra questi troviamo TOVE. La metodologia seguita per la definizione di un’ontologia è, sommariamente, quella qui illustrata. Per poter completare e realizzare un’ontologia, secondo quanto detto nelle fasi di sviluppo della stessa, deve essere scelto un linguaggio di rappresentazione dei concetti, ossia in grado di supportare la meta-ontologia. Tra tali linguaggi si hanno le reti semantiche. Per introdurre queste e comprendere meglio i vantaggi che derivano dalla loro adozione, è opportuno dare una definizione di base di conoscenza. La base di conoscenza. Una base di conoscenza (KB) è un insieme di asserzioni (o affermazioni) che riguardano un certo mondo (o dominio) che si intende rappresentare. Per realizzare una KB è necessario eseguire le seguenti operazioni:
Per rappresentare la KB si può ricorrere al linguaggio della logica e i vantaggi che derivano da tale rappresentazione sono diversi:
Al tempo stesso, la rappresentazione della KB attraverso la logica dei predicati del primo ordine presenta degli svantaggi:
In sostituzione della rappresentazione della KB attraverso un linguaggio di logica del primo ordine sono state adottate le reti semantiche che sono facilmente esprimibili attraverso logiche del primo ordine e che sono in grado di esprimere ogni formula della logica (si affermerà, in seguito, che le reti semantiche costituiscono una rappresentazione equivalente a quella della logica del primo ordine per ciò che riguarda la KB). Le reti semantiche. La rappresentazione tramite reti semantiche venne introdotta da Ross Quillian nel 1965 per simulare computazionalmente il modello "associativo" in cui la memoria umana organizza le informazioni semantiche. Quillian era alla ricerca della soluzione ad uno dei problemi dell’Intelligenza Artificiale: come venga ricordato il significato di una parola. La soluzione che propose è assai semplice: si ricorda il significato di una parola associando ad essa tutte le altre parole che in qualche modo servono a definire il suo significato. Il significato non sarebbe pertanto qualcosa di assoluto, ma sempre qualcosa di relativo agli altri significati disponibili. Al tempo stesso la teoria di Quillian discendeva dai programmi degli anni Cinquanta che erano stati realizzati per tentare la traduzione automatica da una lingua all’altra, alcuni dei quali impiegavano tecniche simili per rappresentare il significato delle parole, per esempio le "reti correlazionali" e le "costellazioni" di Silvio Ceccato e, appunto, le "reti semantiche" di Margaret Masterman, la prima a coniare il termine. Il modello della memoria che Quillian propose era una estensione e generalizzazione di tutti questi concetti. In Informatica per rete si intende un grafo, una rappresentazione grafica delle relazioni che sussistono fra gli elementi di un insieme. Ogni elemento viene detto nodo della rete e viene connesso tramite un arco a nodi che rappresentano altri elementi in relazione con esso. Una rete semantica è un grafo relazionale, ovvero una rete nella quale ogni arco specifica anche quale tipo di relazione sussista fra i due nodi che congiunge. L’arco non si limita pertanto ad affermare che due elementi sono in relazione, ma specifica anche in quale relazione semantica essi siano. Quillian ipotizza che la memoria contenga una rete molto intricata di nodi corrispondenti a parole: la parola “padre” può essere connessa a quelle “madre”, “figlio”, …, da una relazione di tipo “parentela”, mentre può essere connessa a quella “cane”, “albero”, …, dalla relazione di tipo “maschile”, e a tante altre parole da tante altre relazioni. Il “significato” di una parola (o, più in generale, di un concetto) è l'insieme di tutti i nodi che possono essere raggiunti a partire dal nodo che la rappresenta e continuando a “navigare” finché possibile di arco in arco. La rete semantica asserisce il fatto intuitivo che la definizione di un oggetto non può fare a meno della definizione degli oggetti con cui è in relazione e, in ultima analisi, del contesto in cui l’oggetto è situato. Per definizione ogni nodo di una rete semantica contiene soltanto una parte dell’informazione che la rete ha a disposizione riguardo l’oggetto rappresentato da quel nodo: gli archi che “escono” da quel nodo costituiscono estensioni naturali dell'informazione contenuta nel nodo. Di arco in arco tale informazione si sparge per una regione della rete che può essere molto ampia. La rete semantica è anche coerente con l’altro fatto intuitivo che è sempre difficile stabilire quali siano i confini dell’informazione relativa ad un oggetto. Una relazione particolarmente importante che può sussistere fra i nodi di una rete semantica è quella di “individuo che appartiene ad un insieme”, ovvero di un nodo che è congiunto ad un altro nodo tramite un arco “appartiene” (da un arco “IS A”). In tal modo si genera infatti una tassonomia gerarchica, una classificazione degli oggetti in classi sempre più astratte (“gatto” IS A “felino” IS A “mammifero” IS A “animale” IS A ... ). Una delle conseguenze della relazione di appartenenza è l’ereditarietà delle proprietà: l’oggetto che appartiene ad una certa classe ne eredita anche le sue proprietà. Per esempio, se i felini sono mammiferi, la classe dei felini eredita la proprietà che i mammiferi non fanno le uova: non c’è bisogno di dire esplicitamente “i felini non fanno le uova”. Una rete di relazioni gerarchiche, grazie proprio a questo principio di ereditarietà, può far risparmiare parecchie risorse computazionali, nel senso che molte informazioni possono essere inferite direttamente. Gary Hendrix (1977) dimostrò l'equivalenza della rete semantica alla logica dei predicati, ampliando in tal modo la sua originaria funzione di passiva rappresentatrice di conoscenza. Le reti semantiche di Hendrix possono innanzitutto essere “partizionate”: ogni sotto-rete descrive un mondo separato e sta in qualche relazione con le altre reti. Per esempio, è possibile imporre una relazione gerarchica definendo una rete come nodo di un’altra rete. Alcuni archi svolgono il ruolo di quantificatori, inclusioni e operatori logici. Per esempio, per quantificare universalmente (“per-ogni”) una sotto-rete si impone un arco di tipo “per ogni” collegato dall’esterno al nodo che rappresenta tale sotto-rete. Analogamente per “negare” la sotto-rete si collega la sotto-rete con un arco “NOT”, e così via. Una variante di questo approccio è data dalle “reti proposizionali” inventate da Stuart Shapiro nel 1971, nelle quali ogni nodo era una proposizione (quella di Shapiro fu anche la prima implementazione a reti dell’intera logica dei predicati). L’approccio “partizionato” di Hendrix alle reti semantiche è indispensabile, per esempio, quando si debbano esprimere dipendenze temporali (un certo contesto capita prima di un altro). Nel 1975 William Woods propose di dotare la rete semantica di una semantica introducendo un formalismo rigoroso analogo a quello della semantica per la logica dei predicati. In particolare mosse una critica radicale all’uso degli archi nelle reti: nonostante essi possano rappresentare concetti molto diversi, tutti gli archi vengono trattati indiscriminatamente allo stesso modo. Secondo Woods non esisteva alcuna “teoria” delle reti semantiche: i sistemi a rete semantica erano molto eterogenei. Discendenti diretti delle riflessioni avanzate da Woods sulla mancanza di formalismo delle reti semantiche sono, nella seconda metà degli anni settanta, le reti semantiche ad ereditarietà strutturata e, successivamente, il sistema KL-ONE. Prima di passare a descrivere i sistemi KL-ONE che, come appena detto, rappresentano i successori delle reti semantiche, è doveroso mettere in evidenza quali siano i vantaggi che queste offrono e, nello stesso tempo, i limiti che impongono. I motivi del successo delle reti semantiche sono diversi. Esse adottano un formalismo grafico e sono facili da comprendere e da gestire dal punto di vista dell’implementatore. Inoltre, pur realizzando una rete molto vasta è facile capire quali interrogazioni saranno efficienti: si ha una facilità di visualizzazione dei passi attraversati dalla procedura di inferenza e una semplicità del linguaggio di interrogazione che non consente interrogazioni troppo complesse. Tuttavia le reti semantiche presentano dei limiti, in quanto occorrono delle reti grandi e complesse per rappresentare concetti abbastanza semplici e non hanno una semantica formale, ossia delle convenzioni che siano universalmente accettate su ciò che rappresenta una rete. Un altro importante limite delle reti semantiche è riferito alla incapacità di rappresentare relazioni che abbiano parità maggiore di due. I grafi, infatti, possono rappresentare solo relazioni binarie. Per implementare, nelle reti semantiche, predicati con più di due argomenti, per ogni argomento del predicato si crea una relazione binaria. Le reti KL-ONE. Le reti KL-ONE sono state sviluppate a partire dalle ricerche sulle reti semantiche condotte da Brachman (1985) e presentano alcuni aspetti metodologici di notevole interesse:
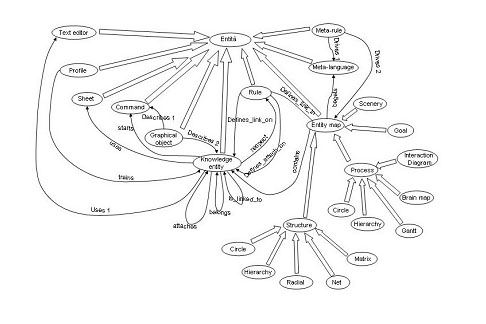
Le reti KL-ONE prevedono un’ereditarietà multipla: un concetto può ereditare da più di un sopraconcetto. In questo caso la rete semantica non è più un albero ma un grafo. Nel caso dell’ereditarietà multipla si possono verificare casi di inconsistenza che non sono facilmente risolvibili come dimostra l’esempio seguente: Richard Nixon era un quacchero, dunque un pacifista, ma era anche un repubblicano, dunque non pacifista. Tali conflitti non possono essere risolti se non sfruttando un'informazione aggiuntiva che espliciti un criterio di preferenza per uno dei percorsi in conflitto. I concetti generici definiti in una rete KL-ONE sono rappresentati graficamente da un ellisse e ogni concetto generico può essere descritto attraverso relazioni con altri concetti generici mediante ruoli (ogni rete semantica ha una radice – root – a partire dalla quale sono definiti tutti i concetti che non siano sottoclassi di concetti più generali). Un ruolo è rappresentato tramite un arco orientato contrassegnato con un quadratino inscritto in un cerchio ed etichettato con il nome del ruolo stesso. Un ruolo generico è un modo per esprimere una relazione potenziale fra le istanze di concetti generici. I concetti sono organizzati in una tassonomia (gerarchia) attraverso archi di sussunzione (o di superconcetto) rappresentati da frecce a doppio tratto. Un concetto X è un sussulto di un altro concetto Y se è meno generale di Y, ossia se tutte le sue istanze sono anche istanze di Y. La relazione di sussunzione permette di realizzare il meccanismo dell’ereditarietà strutturata che le reti KL-ONE prevedono: ogni concetto eredita dai suoi superconcetti tutti i ruoli e le strutture valide per il concetto padre (corrisponde alla relazione insiemistica di sottoinsieme). Attraverso la relazione di istanziazione, invece, si stabilisce una relazione tra un’istanza e un concetto (corrisponde alla relazione insiemistica di appartenenza). Di seguito è riportato un esempio di rete KL-ONE che chiarisce le definizione appena enunciate
I concetti generici rappresentano classi di individui, mentre quelli individuali (istanze) indicano individui specifici e vengono detti riempitori (filler) di un ruolo. Il concetto in cui termina il ruolo viene detto restrizione di valore (value restriction – VR) del ruolo e a questo può essere associata una restrizione di numero che esprime il limite minimo e quello massimo di riempitori che un ruolo può avere. Se per un ruolo non è indicata alcuna restrizione di numero si assume che il limite inferiore sia 0 e che il limite superiore sia N (N indica che non esiste un numero prefissato di riempitori per quel ruolo). Un’altra importante proprietà posseduta dalle reti KL-ONE è l’ereditarietà dei ruoli che si affianca a quella dei concetti. È possibile effettuare modifiche alla struttura dei ruoli ereditati, purché non determinino conflitti con le strutture ereditate (si può modificare la restrizione di numero di un ruolo se la nuova restrizione è più vincolante di quella ereditata). Gli archi di sussunzione e i ruoli esprimono un insieme di condizioni per la definizione di un concetto. Se tali condizioni, oltre ad essere necessarie, sono anche sufficienti, allora il concetto si dice definito; altrimenti esso è primitivo. I concetti primitivi sono indicati con un asterisco (si assume che gli altri siano definiti). |
|
|
|