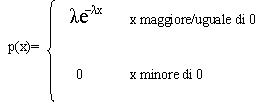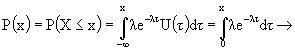VIAGGIO NEL DNA DELLE ORGANIZZAZIONI
La progettazione dei processi(r)

![]()
![]()
![]()
![]()
|
VIAGGIO NEL DNA DELLE ORGANIZZAZIONI La progettazione dei processi(r)
|
|
|
Come abbiamo già accennato, nonostante sia diffusa la voce, più o meno autorevole, secondo cui l’approccio per processi è più moderno ed efficace di quello per strutture, la nostra opinione è che questa sia una visione di parte di un problema ben più ampio dove i due approcci non solo possono ma devono convivere ed integrarsi. Constateremo in questo stesso capitolo che ambedue gli approcci sono parziali e settoriali nonostante che sia erroneamente ritenuto che quello per processi sia più oneroso ma completo ed esaustivo. Anche questo, come vedremo quando parleremo della Qualità e dell’Organizative Knowledge & Change Management, presenta i suoi limiti se non è visto in un contesto sistemico. La logica dei processi
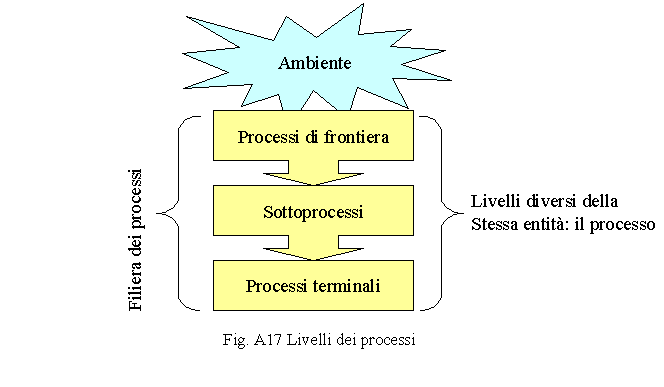
nasce simultaneamente in più aree: o quella classica industriale, dove il processo produttivo deve progressivamente consentire alle macchine o ai robot di sostituire l’uomo per le attività ripetitive ad alta frequenza ed a basso contenuto di valore aggiunto; o quella dell’ICT, dove l’approccio classico funzionale è stato progressivamente sostituito con quello per processi in modo da considerare il sistema informativo come parte integrante degli stessi anche in funzione del contributo che tali tecnologie possono dare alla informatizzazione ed alla conseguente automazione degli stessi; o quella dei revisori o dei controlli interni, che rappresentano i processi per poter verificare i punti di debolezza degli stessi e quindi inserire attività di controllo per abbattere i rischi dell’Organizzazione a cui appartengono; o quella della qualità, che è passata da una logica di applicazione di norme e procedure ad un sistema di progettazione continua e gestione dei processi; o quella del project management, dove l’approccio classico del PERT e del GANTT viene progressivamente integrato in un metodo che consenta di industrializzare l’Organizzazione di sviluppo e di controllo dei progetti evolvendosi verso quello che è definito company-wide project management; o quella dell’organizzazione dove l’approccio classico per strutture è stato troppo spesso inutilmente sostituito da un approccio per processi considerato alternativo piuttosto che affiancato; o quella del controllo di gestione o meglio, in particolare, della metodologia ABC-ABM (Activity Based Costing – Activity Based Management) dove tutti i costi sono ricondotti ai processi o meglio in capo alle attività dove si manifestano. Ma cos’è un processo? Potremmo definirlo una forma d’energia in grado di trasformare un’altra forma d’energia in un’altra ancora pagando all’ambiente un prezzo in termini d’entropia. Oppure potremmo puù semplicemente dire che è un insieme di attività coordinate secondo certe sequenze finalizzato al raggiungimento di un determinato scopo. Ambedue le definizioni sono giuste e scientificamente corrette. La differenza risiede nel fatto che la prima è di tipo sistemico, e quindi olistica ed ecologica, la seconda è di tipo meccanico. I processi possono essere rappresentati a due livelli. Il primo livello tratta quelli che vengono definiti macroprocessi, processi di frontiera (Jacobson). Questi sono, di fatto, processi come tutti gli altri ma presentano la caratteristica di poter essere individuati immediatamente a livello strategico. Il secondo livello riguarda quelli che sono chiamati sottoprocessi, ovvero processi componenti (fig. A17).
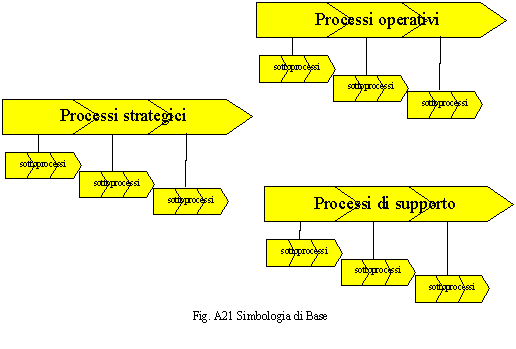
I processi di frontiera, in genere, sono suddivisi in processi di business, di supporto e strategici. I processi di business sono quelli che è possibile immediatamente collegare al mondo esterno, al business, per l’appunto, o, più in generale, al mondo dei prodotti-servizi, che l’Organizzazione, profit o no profit, quale essa sia, è in grado di fornire, in sintesi quelli che impattano con l’ambiente. I processi di supporto sono quelli che non impattano immediatamente con l’ambiente, ma la cui funzione è fondamentale per lo sviluppo e la gestione del business o più in generale per la mission dell’organizzazione. I processi strategici sono quelli necessari a formulare le strategie, pianificare le attività, controllare l’esecuzione delle stesse. In realtà parliamo sempre degli stessi oggetti: i processi. Tale distinzione non giustifica la presenza d’entità distinte, come avviene in tante metodologie o sistemi per la rilevazione, l’analisi e la progettazione dei processi, ma al massimo una distinzione a livello d’attributo qualificatore di un’unica entità, per l’appunto: il processo. Anche i sotttoprocessi non sono un’entità a sé stante ma una tipologia, un semplice attributo, della stessa entità. Come già accennato, un processo di frontiera può svilupparsi in più sottoprocessi secondo una logica di sviluppo dall’alto in basso (top-down) fino a comporre una filiera. Possiamo definire processi terminali quelli che non si scompongono in altri sottoprocessi e sono collocati nel livello più basso della filiera, anche in questo caso, non potremo parlare d’entità vere e proprie ma semplicemente di un attributo che li distingue. Tale attributo che distingue il processo nell’ambito della filiera dei processi non è necessario che sia esplicito poiché è già implicito all’interno della rappresentazione della filiera ed è assunto in funzione della posizione d’ogni processo nell’ambito della stessa. Non è altrettanto implicita la distinzione fra processi di business, di supporto e strategici, infatti, non è possibile ricavare questa automaticamente dal loro posizionamento nell’ambito della filiera dei processi.
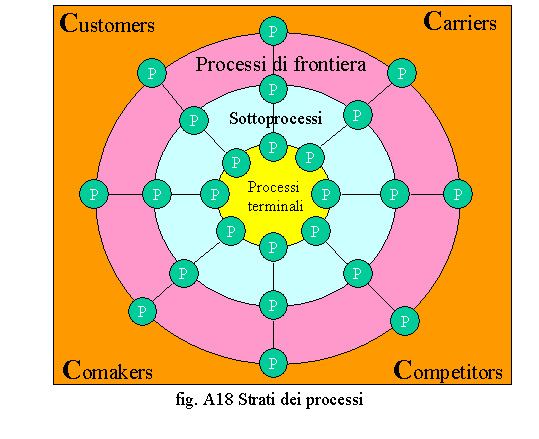
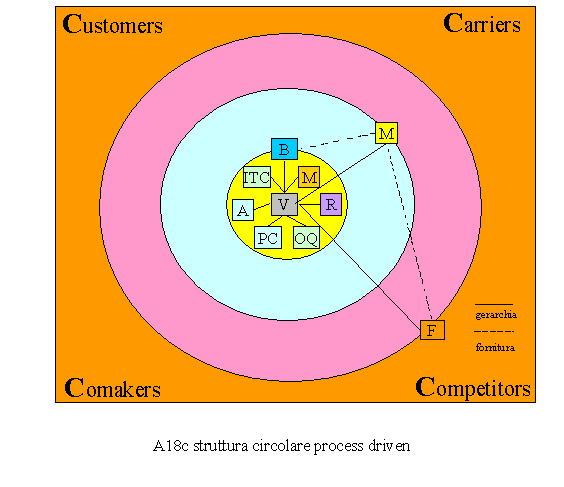
In figura A18 è rappresentata una nostra visione (circolare), dove i processi s’irradiano dai processi endogeni (processi terminali), per tramite dei processi intermedi (sottoprocessi) verso i processi esogeni (processi di frontiera) attraverso i quali l’Organizzazione impatta con il mercato composto di Comakers (alleati), Customers (clienti), Competitors (concorrenti) e Carriers (vettori). E’ una visione, a nostro avviso, più equilibrata rispetto alla gerarchica dove tutti i processi assumono pari dignità pur coprendo ruoli diversi nell’ambito dell’Organizzazione. In tale schema, i processi possono essere logicamente avvicinati verso le quattro componenti di mercato creando una distribuzione intorno all’attore di mercato verso cui sono orientati. La densità dei processi nell’intorno di ogni attore di mercato fa capire quanto l’Organizzazione copra con i sui processi clienti, partners, concorrenti, canali o vettori commerciali. Come è possibile integrare processi e strutture? Ciò può essere fatto
attraverso una procedura che può essere definita di allocazione dei processi
alle strutture (process allocation) e si compone, in liea di massima, delle
seguenti fasi: 1. individuazione per ogni processo di frontiera di una struttura process owner 2. individuazione per ogni sottoprocesso si una struttura process owner 3. definizione delle strutture di governo di Aree di processo omogenee 4. definizione delle strutture di governo delle risorse 5. definizione delle strutture amministrative 6. definizione delle strutture per lo sviluppo ed il governo dell’organizzazione interna e della qualità 7. definizione delle strutture per lo sviluppo ed il governo dell’ICT 8. definizione delle strutture di pianificazione e controllo 9. definizione delle strutture di marketing 10.
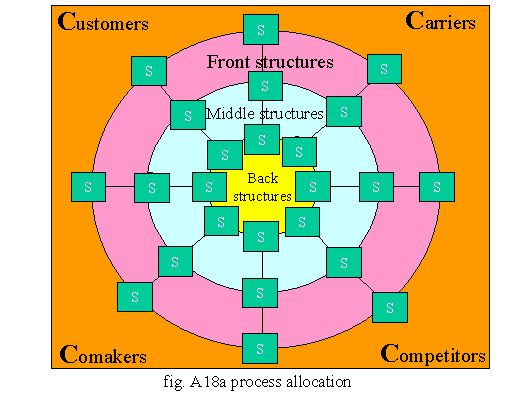
definizione delle strutture di vertice dell’Organizzazione. In fig. A18a è rappresentata tale procedura. Questa deriva direttamente dalla nostra visione circolare di irraggiamento dei processi. Si vede chiaramente che nascono spontaneamente tre livelli diversi di struttura: le front, le middle e le back. Le prime impattano direttamente con l’ambiente e, in genere, con gli eventi, attivando i processi di frontiera e quindi non possono che essere le responsabili dell’intero processo. Sono queste infatti che operano a contatto con l’ambiente e che devono garantire i risultati. Naturalmente un processo complesso presuppone l’utilizzo di processi interni portanti, i sottoprocessi, e di processi terminali. Questi ultimi devono essere garantiti da strutture che si comporteranno, all’interno dell’Organizzazione, come fornitori di servizi interni quindi direttamente responsabili della efficacia ed efficienza degli stessi, nei confronti del process owner che gestisce il processo di livello gerarchico immediatamente superiore. La matrice di fig. A18a garantisce la copertura di tutti i processi. Una volta che tutti i processi sono stati coperti in termini di responsabilità occorre pensare alla gestione di aree omogenee di processi che hanno un livello di complessità tale da richiedere un coordinamento di livello superiore, alla gestione delle risorse umane e strumentali, della logistica, dell’organizzazione e delle tecnologie. Occorre quindi preoccuparsi dell’amministrazione e della pianificazione e controllo ed infine della struttura di vertice.
Tale approccio non è di fatto bottom up, come potrebbe sembrare, ma process driver cioè orientato al governo di tutti i processi. Naturalmente è possibile adottare qualsiasi tipo di struttura, purchè compatibile con la copertura dei processi.
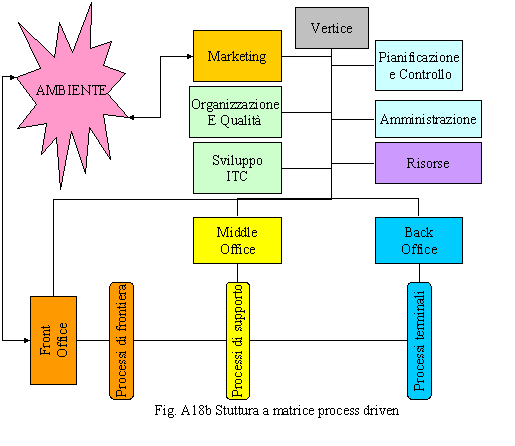
La struttura a matrice che proponiamo, riportata in fig. A18b, è quella che a noi sembra essere la più coerente. Questa rispecchia la naturale divisione dei processi, è coerente con le logiche della process allocation, assicura la copertura dei processi, ottimizza il numero di strutture, è coerente con le logiche della qualità (vision 2000), è compatibile, come vedremo anche per la gestione dei progetti e quindi con le logiche del project management. Un altro vantaggio è che lascia spazio motivazionale alle persone che possono essere motivate dai processi di cui sono responsabili piuttosto che dal ruolo. Pur essendo una struttura a matrice, essendo chiaro il chi fa ed il chi è responsabile di cosa non presenta ambiguità. Il rapporto fra process owners non è gerarchico ma si basa sulla relazione cliente-fornitore e quindi rispecchia le regole naturali imposte dall’ambiente, crea un clima di sana competitività ed un orientamento agli obiettivi piuttosto che ai compiti.
Naturalmente il modello di struttura proposto può essere articolato e personalizzato in sottostrutture specializzate. Come abbiamo già visto per le strutture, anche per i processi esistono varie tipologie di rappresentazione, ovvero un linguaggio grafico attraverso il quale esplicitare in modo chiaro il funzionamento degli stessi. Esistono naturalmente vari formalismi e delle varianti di tale linguaggio che possono differenziarsi in funzione degli obiettivi che si prefigge un progetto organizzativo o informatico piuttosto che un altro. Ma esiste un qualcosa che possa legare tali linguaggi, un filo conduttore comune che possa essere valido sempre e comunque? Siamo convinti che esiste e che è, di per sé semplice, come tutte le regole che sono alla base della complessità. Nei prossimi paragrafi cercheremo di spiegare alcuni dei metodi di rappresentazione più utilizzati. Vedremo che taluni sono dei veri e propri standard o riconosciuti come tali ma presentano dei limiti per poter essere considerati dei linguaggi universali. Rammentiamo che il nostro scopo è definire un linguaggio universale il più semplice possibile che possa essere facilmente personalizzato attraverso i suoi componenti base. Una grammatica che possa essere facilmente compresa dagli addetti e dai non addetti ai lavori, con una sua semantica, sintassi e lessico definiti attraverso un procedimento bottom-up di individuazione delle componenti elementari e delle relazioni che le legano per poi creare componenti più complesse quali schemi (patterns), aggregati e viste di sintesi rappresentativi del mondo dell’organizzazione. Il modello della catena del valore di Porter (1990) è un chiaro esempio di un metodo efficace per rappresentare i macroprocessi con un livello di sintesi molto elevato.
In fig. A19 è rappresentato un esempio di catena del valore. Tale rappresentazione non è di per sé sufficiente a coprire il livello strategico. Non può, infatti evidenziare le relazioni che esistono fra l’Organizzazione ed le quattro componenti di mercato Customers, Comakers, Carriers, Competitors.
In fig. A20 è riportato un altro diagramma di Porter che descrive il funzionamento di tutti i processi di un’Organizzazione secondo le logiche della qualità. Come è possibile notare esistono diverse tipologie di rappresentazione nell’ambito della catena del valore di Porter.
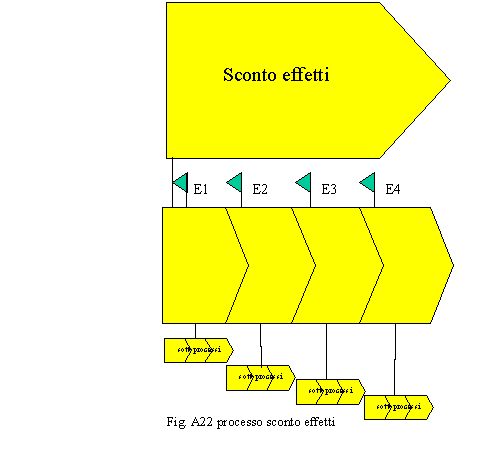
La simbologia di base è comunque quella riportata in fig. A21 dove sono identificati i processi di inizio quelli attivati in modo sequenziale ed i sottoprocessi. Tale rappresentazione non consente di comprendere le relazioni esistenti fra i processi strategici, operativi e di supporto ed inoltre crea, a nostro avviso delle separazioni che, di fatto, non esistono fra queste tipologie che sono più degli attributi dell’entità processo piuttosto che delle entità vere e proprie. Inoltre si dà l’idea di processi che si attivano sequenzialmente mentre tale visione se ha una sua intrinseca validità in termini di sequenza logica potrebbe non risultare vera nei fatti dove gli eventi che scatenano i processi possono non solo essere asincroni ma anche disomogenei in termini di volumi. Consideriamo, per esempio, un’agenzia bancaria e vediamo cosa succede quando il cliente si presenta per scontare un effetto. L’operazione avviene allo sportello sul terminale dell’operatore unico che quindi tratta l’effetto, rilascia la ricevuta e lo archivia. A questo punto l’operatore è pronto per svolgere qualsiasi altra operazione (versamento, prelevamento, estratto conto, ecc.). L’effetto rimane archiviato fino a sera, quando si fanno le quadrature, si prendono tutti gli effetti e si mandano al centro lavorazione effetti. Quest’ultimo, raccolti tutti gli effetti, provenienti da tutte le filiali, attiva la procedura. L’esempio
dimostra che i quattro eventi non sono tutti uguali e sono disomogenei in
termini di volumi: 1. il cliente si presenta allo sportello (tipo di evento: occasionale) con 1 effetto, che viene trattato dall’operatore unico 2. a fine giornata l’operatore unico quadra tutti gli n effetti (tipo di evento: periodico – giornaliero) 3. dopo la quadratura si inviano tutti gli m effetti della filiale al centro lavorazione (tipo di evento: periodico – giornaliero) 4.
ogni notte il centro lavorazione tratta i k effetti di tutte le filiali
(tipo di evento: periodico – giornaliero). Occorre quindi, conciliare il bisogno di una visione logica sequenziale con il rigore necessario a considerare che non è possibile trattare eventi asincroni come se fossero sincroni e volumi disomogenei, poiché ciò porterebbe a sbagliare qualsiasi calcolo sui carichi di lavoro.
Come è possibile notare, nel diagramma sono stati introdotti dei simboli grafici rappresentativi degli eventi. In questo modo è possibile gestire contemporaneamente gli eventi asincroni e la sequenza logica dei processi. Per completare la rappresentazione del modello dei processi a livello strategico occorre introdurre un altro schema (pattern) che possa consentire di descrivere le relazioni intercorrenti fra l’organizzazione ed i quattro componenti fondamentali dello scenario di mercato Customers, Competitors, Comakers e Carriers e quelle con i prodotti/servizi. Esistono vari metodi fra cui quello classico, di cui ci occuperemo in questo specifico paragrafo. Il metodo classico è
nato intorno a pochi simboli ai quali, successivamente, ne sono stati
aggiunti degli altri per migliorarne la lettura e per risolvere dei problemi di
sincronismo o di decisione. In fig. A23 sono riportati i simboli essenziali. Parleremo successivamente dei livelli di semplificazione che possono essere ulteriormente ottenuti, quindi quasi di un ritorno alle origini per rendere il linguaggio elementare.
Siamo convinti che la nostra
ricerca sul linguaggio universale per l’organizzazione deve procedere
attraverso un processo di semplificazione, che conduca ad un linguaggio
semplice per rappresentare modelli complessi. Il flow chart classico presenta queste caratteristiche. Con questo è possibile rappresentare qualsiasi processo.
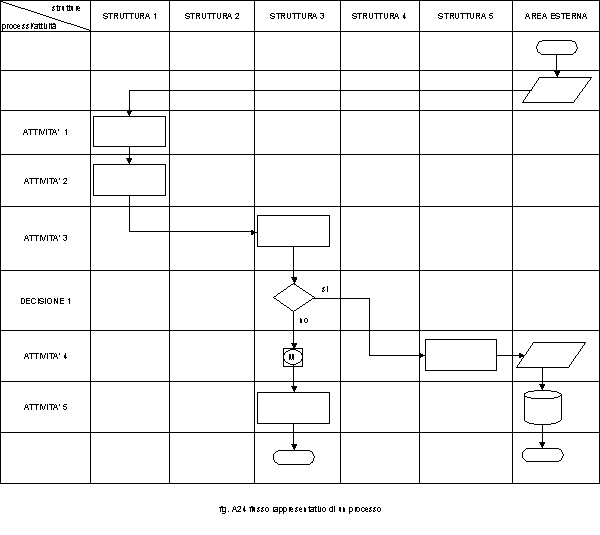
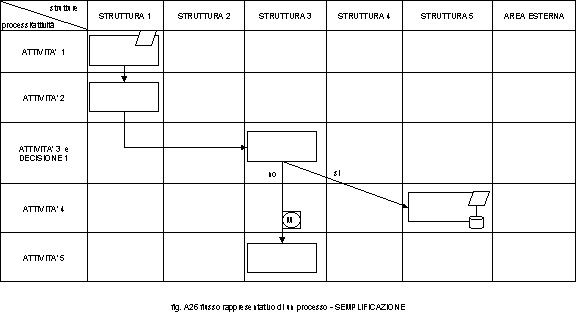
Come è possibile vedere questo è disegnato su di una struttura di tipo matriciale dove sulle colonne sono presenti le strutture e sulle righe le descrizioni delle attività e dei punti di decisione. Seguendo il processo dall’alto in basso, questo è autoesplicante. Proviamo ad ipotizzare, delle ulteriori semplificazioni ed ottimizzazioni rispetto alla notazione classica. In fig. A25 è riportata la tabella di paragone fra i simboli classici e le semplificazioni da noi proposte.
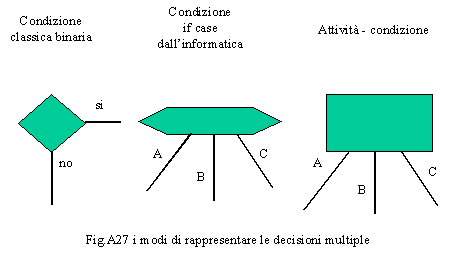
Tale notazione oltre ad essere ancora più essenziale rispetto alla precedente, consente anche di gestire situazioni di decisioni condizionate a percorsi multipli. Infatti dall’attività possono diramarsi più rami ognuno condizionato da una decisione (vedi fig. A27).
Inoltre, la notazione a matrice è bella e funzionale soprattutto su carta, presenta, invece, dei limiti a video in quanto il flusso visualizzato, in certe situazioni, può non far vedere le strutture o la descrizione delle attività perché fuori dal campo visivo. Dovrebbe essere utilizzata una soluzione che consenta di visualizzare, più aree separate, una in alto per le strutture, una a destra per la descrizione delle attività ed un’altra compresa fra le prime due per rappresentare il flow chart. Ciò è fattibile anche se complesso, soprattutto in una soluzione web oriented.
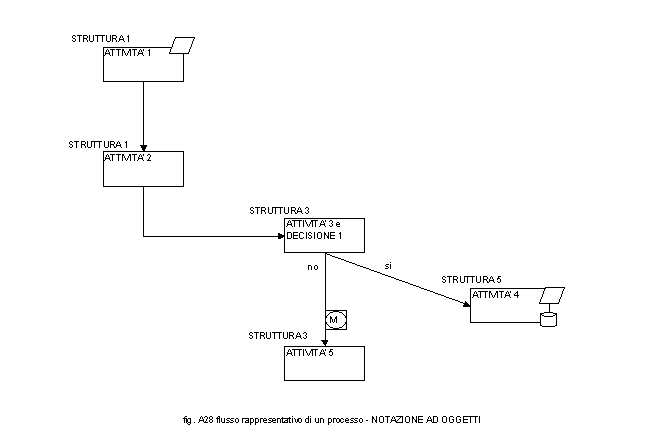
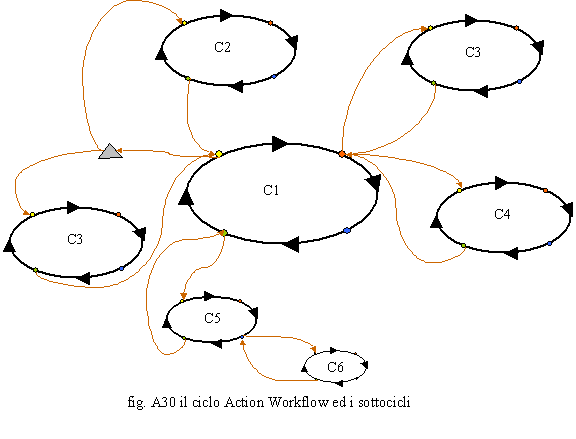
E’ inoltre possibile semplificare tale rappresentazione a matrice con una equivalente ad oggetti. Più precisamente, una soluzione dove la descrizione del processo/attività è inserita all’interno del simbolo grafico che la rappresenta e quella della struttura immediatamente sopra tale simbolo (vedi fig. A28). In tale modo il processo è sempre leggibile in quanto tutti gli attibuti sono collegati direttamente all’oggetto. Questa considera il processo come una serie di cicli interconnessi fra loro che regolano il rapporto Cliente esterno – Organizzazione fornitrice e Cliente Interno – Fornitore Interno. In pratica, immagina che un processo sia che sia rivolto all’esterno e quindi ad un cliente, sia che si svolga all’interno deve sempre vedere due attori, il cliente ed il fornitore, che interagiscono sempre attraverso un ciclo standard che, può attivare altri cicli standard. Si crea quindi una filiera di cicli e sottocicli esattamente come avviene nel caso dei processi e dei sottoprocessi. Sempre secondo tale
metodologia, il ciclo standard si esaurisce in quattro fasi:
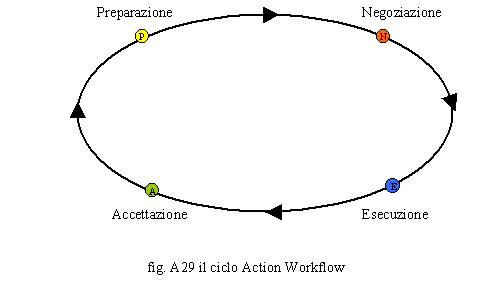
La rappresentazione del ciclo di Action Worflow è quella riportata in fig. A29.
Il Ciclo C1 attiva gli altri cicli secondari che possono a loro volta attivarne altri. Nel dettaglio, C1, nello stato di preparazione, attiva, in base alla condizione, rappresentata da un triangolo, o il ciclo C2 o il Ciclo C3 che ritornano al ciclo C1 solo dopo la conclusione delle rispettive fasi di accettazione. A questo punto il controllo ritorna al ciclo C1 che termina la fase di preparazione ed entra nello stato di negoziazione. In questa fase attiva contemporaneamente, in parallelo, i sottocicli C3 e C4. Quando questi sono completati, il controllo ritorna al ciclo C1 che attiva la fase di esecuzione; in tale stato non sono attivati sottocicli ma le istruzioni proprie previste per tale fase. Una volta terminata la fase d’esecuzione, il ciclo C1 esegue la fase d’accettazione dove attiva il sottociclo C5 che, a sua volta, in cascata (serie), attiva il sottociclo C6. Non appena il sottociclo C6 ha terminato, ripassa in controllo al sottociclo C5, che, a sua volta, al termine delle attività, ripassa il controllo al ciclo principale C1. Il ciclo principale C1 esegue le ultime istruzioni dello stato d’accettazione e termina. La metodologia è sicuramente valida ma presenta alcuni aspetti negativi. Nonostante che il diagramma sia affascinante, poiché simile al diagramma degli stati degli automi, può, per processi complessi, essere di difficile stesura e lettura. Un albero dei processi è sicuramente più semplice, immediato e soprattutto modulare. Inoltre, non è sempre facile ricondurre un processo ai quattro stati fondamentali e ciò provoca, in alcuni casi, il ricorso a delle forzature logiche. Altri sistemi di workflow management utilizzano una notazione più vicina a quella classica e quindi più immediata per gli analisti d’organizzazione. La SADT è considerata, di
fatto, uno standard per la rappresentazione dei processi ed è conosciuto anche
col nome di IDEF0 in quanto è stato inserito contale nome in numerosi
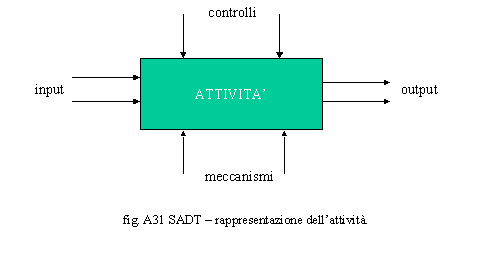
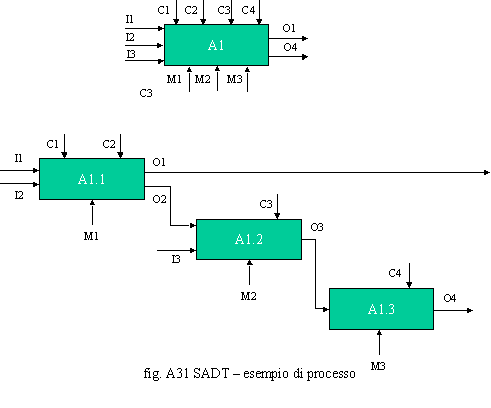
organismi di standardizzazione (ISO, FIPS). L’elemento di base della metodologia SADT è l’attività/processo I concetti fondamentali su cui si basa la SADT sono i seguenti: o il sistema da analizzare e riprogettare è rappresentato tramite modelli descritti per mezzo di un linguaggio grafico o i modelli sono costruiti in termini di attività intese come oggetti scomponibili legate da flussi informativi e di trasformazione o l’analisi è gerarchica, strutturata e modulare o le tipologie di attributi legati agli oggetti sono rigorose e ben definite.
In fig. A31 è riportata la modalità di rappresentazione dell’attività.
Com’è possibile notare, la notazione di rappresentazione in capo ad A1 riassume tutti gli inputs, gli outputs, i controlli ed i meccanismi presenti in tutte le attività componenti. Il diagramma è autoesplicativo. La rappresentazione SADT, se è facile da utilizzare e da interpretare per chi progetta, non è utile per chi deve operare e quindi, nonostante sia uno standard, non può essere definita un liguaggio universale per tutti gli attori dell’Organizzazione ma per specialisti. Ottimizzare, automatizzare ed anche reingegnerizzare drasticamente i processi non è sinonimo di BPR. Vedremo nel paragrafo successivo che le differenze sono notevoli. Qualsiasi ottimizzazione o riprogettazione dei processi può essere considerata un approccio classico, fuorché questo sia effettuato in chiave di business (process driver), in questo caso parleremo di BPR/BPI. Con l’approccio classico si cerca di ottimizzare i processi che fanno parte di un prestabilito dominio d’intervento, in termini d’efficacia e d’efficienza. Con il BPR/BPI si cerca un salto (gap) competitivo rispetto al mercato. La progettazione classica dei processi può essere condotta in vari modi ma è in genere riconducibile ad un metodo standard su cui si applicano delle varianti in funzione dello specifico obiettivo che si intende perseguire. In fig. A32 è riportata quella che può essere definita portante metodologica per la progettazione classica dei processi. La fase di analisi è fondamentalmente diversa in quanto le criticità che emergono derivano soprattutto dal funzionamento dei processi e quindi dai loro fattori d’efficacia e d’efficienza. I carichi di lavoro sono calcolati in modo analogo, ma tengono conto dei tempi propri delle attività, della complessità della rete di relazioni che le interconnette, nonché dell’iter decisionale che ha attivato, tramite le condizioni, un ramo d’attività piuttosto che un altro. Tali meccanismi saranno spiegati con maggior dettaglio nel paragrafo dedicato alla valutazione dei processi. La fase di riprogettazione è focalizzata sui processi e si pone l’obiettivo di eliminare tutte le criticità riscontrate, nel suo ambito si valuta l’adeguatezza di ruoli e posizioni organizzative a presiedere le attività, si ridisegnano processi e ruoli, si ridisegnano le strutture, si ricalcolano i carichi di lavoro, si confrontano i processi riprogettati con quelli in essere per valutare la fattibilità del progetto, si calcolano i recuperi in termini d’efficacia, d’efficienza e d’organico. Per una maggior comprensione della dinamica di
svolgimento dell’intervento, riportiamo, a seguire, per ogni fase, le sottofasi
componenti con una breve spiegazione: 1. FASE 1: rilevazione 1.1. dominio — è essenziale, prima di operare, rendersi conto del dominio dell’intervento; occorre capirne i confini poiché, essendo questo piuttosto complesso, per ogni processo occorrono tempi di rilevazione e di riprogettazione considerevoli, un errore di valutazione sulla sua estensione, può compromettere i tempi progettuali e renderlo inefficace o tardivo, sempre che non abortisca prima per sfiducia del committente; 1.2. strutture — anche in un intervento per processi è necessario rilevare le strutture in essere per conoscere il funzionamento dei meccanismi di coordinamento, di quelli di comunicazione istituzionale nonché le responsabilità; per ogni unità organizzativa dovranno essere rilevati i processi o i sottoprocessi gestiti; 1.3. ruoli ed organici — all’interno di ogni unità organizzativa dovranno essere rilevati i ruoli, le posizioni organizzative e gli organici assegnati; 1.4. processi — saranno disegnati tutti i processi facenti parte del dominio d’intervento; per ogni processo sarà disegnato il flusso e sarà definito il chi fa cosa all’interno dello stesso, assegnando ruoli e posizioni organizzative alle attività componenti; 1.5. volumi e tempi — dovranno essere rilevati, per periodi significativi, i volumi lavorati per processo e poi occorrerà distribuire gli stessi in capo alle attività tenendo conto delle frequenze d’accadimento dei singoli rami componenti i processi (vedi il paragrafo specifico relativo alla valutazione dei processi); dovranno inoltre essere rilevati per ogni attività componente il singolo processo, i tempi standard unitari; questi possono essere calcolati o tramite misurazioni o attraverso medie di tempi dichiarati; ciò è fondamentale per il successivo calcolo dei carichi di lavoro. 2. FASE 2: analisi 2.1. criticità e punti di forza — a questo punto, sarà necessario tirare le somme in termini di punti di forza e di punti di debolezza; l’analisi terrà conto soprattutto dell’efficacia, efficienza e qualità dei processi, ma porrà la giusta attenzione anche alle sensazioni trasmesse dagli intervistati all’intervistatore, in particolare sui malfunzionamenti segnalati, sul clima aziendale, sullo stile del management, sui conflitti, sulle situazioni di stallo, sul livello di comunicazione, sul livello di formazione, sulle necessità strumentali e formative; 2.2. carichi di lavoro e dimensionamento — avendo a disposizione i tempi standard ed i volumi rilevati dalla fase precedente è possibile calcolare ed analizzare per ogni Processo-ruolo-posizione organizzativa i carichi di lavoro (Carico di lavoro = ∑ tempi standard * volumi lavorati), riportarli in capo ad un periodo annuale, tradurli quindi in termini di risorse virtuali (Risorse virtuali = Carichi di lavoro annui / tempo netto disponibile) e stimare se, nella situazione in essere (as is) sia presente una situazione d’eccesso o di carenza di risorse; 2.3. linee guida — poiché gli interventi sui processi richiedono tempi lunghi, spesso, si dà un’anticipazione dei risultati in modo che l’Organizzazione possa intervenire prima della conclusione del progetto; per evitare che le soluzioni però siano difformi da quella finale si redigono delle linee guida che servono proprio a dare un indirizzo alle azioni correttive ritenute più urgenti; 3.
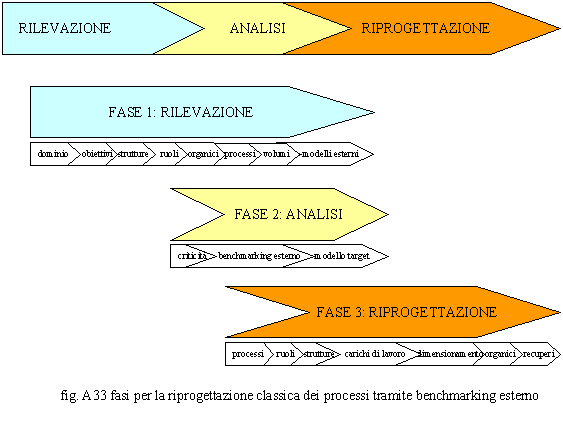
FASE 3: riprogettazione 3.1. processi ― contrariamente a quello che avviene nell’approccio per strutture, si riprogettano i processi; ciò può avvenire in modo soft o radicale, nel primo caso parleremo di ottimizzazione, nel secondo di reingegnerizzazione dei processi; si riprogettano quindi le cose che si fanno, il come vengono fatte, il chi le fa e la rete di relazioni che lega tutte le attività nell’ambito di un processo, nonché quelle che legano i processi in filiere; 3.2. ruoli, posizioni organizzative e strutture ― una volta riprogettati i processi, si definiscono i ruoli-posizioni organizzative (activity owners) responsabili delle attività e le strutture organizzative responsabili dei processi (process owners); si creano quindi le strutture di coordinamento di livello superiore (centri di responsabilità); si cerca, infine, di conciliare le necessità di governo dei processi, con le situazioni e le aspettative degli uomini; 3.3. carichi di lavoro, dimensionamento, organici ― riutilizzando gli stessi volumi rilevati, sono ricalcolati i carichi di lavoro in capo ai processi ed ai nuovi ruoli-posizioni organizzative e, quindi, le risorse virtuali; sono poi identificati tutti gli organici da assegnare alle nuove unità organizzative; 3.4. recuperi ― sono calcolati i recuperi in termini di risorse paragonando la situazione che si propone (to be) con quella in essere (as is); tali recuperi vengono tradotti in costi annuali e proiettati in un triennio; si confrontano poi i costi previsti per l’attuazione del progetto con i recuperi e si verifica dove si pone il punto d’equilibrio (break-even point). Anche nella progettazione dei processi è possibile adottare il metodo del benchmarking interno o esterno. Questo presuppone la conoscenza dei modelli di riferimento presenti sul mercato, dei parametri di valutazione degli stessi e di confronto con l’Organizzazione oggetto dell’intervento. Tale aspetto è sicuramente critico perché è fortemente legato ai processi ed alle tecnologie utilizzate e quindi non è detto che possa essere applicato alla realtà che s’intende riorganizzare. Questo è quello che ci proponiamo di ottenere attraverso la genetica d’impresa: rendere disponibili modelli e parametri che possono essere utili per chiunque intenda riprogettare un’Organizzazione o sue aree componenti. In fig. A33 sono riportate
le fasi metodologiche per un intervento di riprogettazione dei processi tramite
benchmarking esterno. Com’è possibile notare il benchmarking consente di risparmiare i tempi relativi al calcolo del dimensionamento degli organici del modello organizzativo in essere in quanto i confronti possono essere effettuati per macrograndezze.
A seguire riportiamo il dettaglio delle fasi metodologiche di una riprogettazione dei processi classica condotta con il benchmerking esterno. 1. FASE 1: rilevazione 1.1. dominio — è essenziale, prima di operare, rendersi conto del dominio dell’intervento; occorre capirne i confini poiché, essendo questo piuttosto complesso, per ogni processo occorrono tempi di rilevazione e di riprogettazione considerevoli, un errore di valutazione sulla sua estensione, può compromettere i tempi progettuali e renderlo inefficace o tardivo, sempre che non abortisca prima per sfiducia del committente; 1.2. strutture — anche in un intervento per processi è necessario rilevare le strutture in essere per conoscere il funzionamento dei meccanismi di coordinamento, di quelli di comunicazione istituzionale nonché le responsabilità; per ogni unità organizzativa dovranno essere rilevati i processi o i sottoprocessi gestiti; 1.3. ruoli ed organici — all’interno di ogni unità organizzativa dovranno essere rilevati i ruoli, le posizioni organizzative e gli organici assegnati; 1.4. processi — saranno disegnati tutti i processi, a livello macro, facenti parte del dominio d’intervento; per ogni processo sarà disegnato il flusso e sarà definito il chi fa cosa all’interno dello stesso, assegnando ruoli e posizioni organizzative alle attività componenti; 1.5. volumi e tempi — dovranno essere rilevati, per periodi significativi, i volumi lavorati per processo; saranno rilevati, sempre a livello macro i dati quantitativi dei processi, tempi di lavorazione, durate, scarti generati, ecc.; tali dati saranno fondamentali per effettuare dei confronti con i modelli esterni. 1.6. modelli esterni — saranno identificati sul mercato i modelli, di successo, più attinenti all’Organizzazione su cui si sta intervenendo; questi saranno oggetto di confronto nella successiva fase di analisi; 2. FASE 2: analisi 2.1. criticità e punti di forza — a questo punto, sarà necessario tirare le somme in termini di punti di forza e di punti di debolezza; l’analisi terrà conto soprattutto dell’efficacia, efficienza e qualità dei processi, ma porrà la giusta attenzione anche alle sensazioni trasmesse dagli intervistati all’intervistatore, in particolare sui malfunzionamenti segnalati, sul clima aziendale, sullo stile del management, sui conflitti, sulle situazioni di stallo, sul livello di comunicazione, sul livello di formazione, sulle necessità strumentali e formative; 2.2. bechmarking esterno e modello target— si confrontano le performance del modello in essere con quelle dei modelli esterni e si valutano i parametri di processo; si sceglie quindi il modello migliore (target) e si valuta il gap esistente fra questo e quello in essere; 3.
FASE 3: riprogettazione 3.1. processi ― si riprogettano i processi conformemente a quanto prevede il modello target; ciò può avvenire in modo soft o radicale, nel primo caso parleremo di ottimizzazione, nel secondo di reingegnerizzazione dei processi; si riprogettano quindi le cose che si fanno, il come vengono fatte, il chi le fa e la rete di relazioni che lega tutte le attività nell’ambito di un processo, nonché quelle che legano i processi in filiere; 3.2. ruoli, posizioni organizzative e strutture ― una volta riprogettati i processi, si definiscono i ruoli-posizioni organizzative (activity owners) responsabili delle attività e le strutture organizzative responsabili dei processi (process owners); si creano quindi le strutture di coordinamento di livello superiore (centri di responsabilità); si cerca, infine, di conciliare le necessità di governo dei processi, con le situazioni e le aspettative degli uomini; 3.3. carichi di lavoro, dimensionamento, organici ― riutilizzando gli stessi volumi rilevati, sono ricalcolati i carichi di lavoro in capo ai processi ed ai nuovi ruoli-posizioni organizzative e, quindi, le risorse virtuali; sono poi identificati tutti gli organici da assegnare alle nuove unità organizzative; 3.4. recuperi ― sono calcolati i recuperi in termini di risorse paragonando la situazione che si propone (to be) con quella in essere (as is); tali recuperi vengono tradotti in costi annuali e proiettati in un triennio; si confrontano poi i costi previsti per l’attuazione del progetto con i recuperi e si verifica dove si pone il punto d’equilibrio (break-even point).
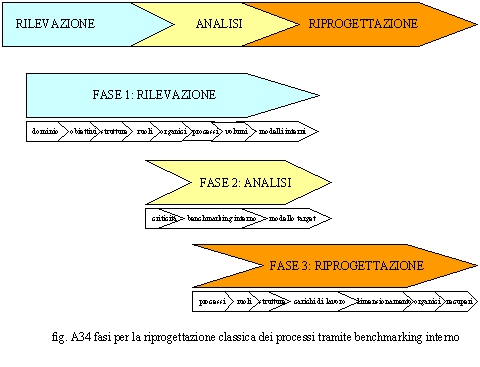
E’ possibile riprogettare i processi traverso un benchmarking interno. Questo, in genere viene utilizzato per standardizzare Aree dell’organizzazione di cui, a fronte di un unico modello logico, esistono più istanze (filiali, agenzie, magazzini distribuiti, ecc.). Tale approccio è molto utile quando esistono aziende simili all’interno di uno stesso gruppo e si intende fonderle in un’unica organizzazione o si intenda standardizzare il loro modo d’operare, In fig. A34 sono riportate
le fasi metodologiche relative ad un intervento di riprogettazione dei processi
con benchmarking interno ed a seguire è riportato il dettaglio delle sottofasi. 1. FASE 1: rilevazione 1.1. dominio — è essenziale, prima di operare, rendersi conto del dominio dell’intervento; occorre capirne i confini poiché, essendo questo piuttosto complesso, per ogni processo occorrono tempi di rilevazione e di riprogettazione considerevoli, un errore di valutazione sulla sua estensione, può compromettere i tempi progettuali e renderlo inefficace o tardivo, sempre che non abortisca prima per sfiducia del committente; 1.2. strutture — anche in un intervento per processi è necessario rilevare le strutture in essere per conoscere il funzionamento dei meccanismi di coordinamento, di quelli di comunicazione istituzionale nonché le responsabilità; per ogni unità organizzativa dovranno essere rilevati i processi o i sottoprocessi gestiti; 1.3. ruoli ed organici — all’interno di ogni unità organizzativa dovranno essere rilevati i ruoli, le posizioni organizzative e gli organici assegnati; 1.4. processi — saranno disegnati tutti i processi, a livello macro, facenti parte del dominio d’intervento; per ogni processo sarà disegnato il flusso e sarà definito il chi fa cosa all’interno dello stesso, assegnando ruoli e posizioni organizzative alle attività componenti; 1.5. volumi e tempi — dovranno essere rilevati, per periodi significativi, i volumi lavorati per processo; saranno rilevati, sempre a livello macro i dati quantitativi dei processi, tempi di lavorazione, durate, scarti generati, ecc.; tali dati saranno fondamentali per effettuare dei confronti con i modelli esterni. 1.6. modelli interni — saranno identificati all’interno i modelli, di successo, simili all’area su cui si sta intervenendo; questi saranno oggetto di confronto nella successiva fase di analisi; 2. FASE 2: analisi 2.1. criticità e punti di forza — a questo punto, sarà necessario tirare le somme in termini di punti di forza e di punti di debolezza; l’analisi terrà conto soprattutto dell’efficacia, efficienza e qualità dei processi, ma porrà la giusta attenzione anche alle sensazioni trasmesse dagli intervistati all’intervistatore, in particolare sui malfunzionamenti segnalati, sul clima aziendale, sullo stile del management, sui conflitti, sulle situazioni di stallo, sul livello di comunicazione, sul livello di formazione, sulle necessità strumentali e formative; 2.2. bechmarking interno e modello target — si confrontano le performance del modello in essere con quelle dei modelli interni e si valutano i parametri di processo; si sceglie quindi il modello migliore (target) e si valuta il gap esistente fra questo e quello in essere; 3.
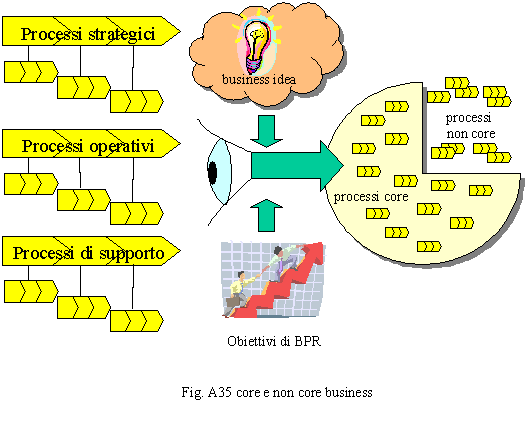
FASE 3: riprogettazione 3.1. processi ― si riprogettano i processi conformemente a quanto prevede il modello target; ciò può avvenire in modo soft o radicale, nel primo caso parleremo di ottimizzazione, nel secondo di reingegnerizzazione dei processi; si riprogettano quindi le cose che si fanno, il come vengono fatte, il chi le fa e la rete di relazioni che lega tutte le attività nell’ambito di un processo, nonché quelle che legano i processi in filiere; 3.2. ruoli, posizioni organizzative e strutture ― una volta riprogettati i processi, si definiscono i ruoli-posizioni organizzative (activity owners) responsabili delle attività e le strutture organizzative responsabili dei processi (process owners); si creano quindi le strutture di coordinamento di livello superiore (centri di responsabilità); si cerca, infine, di conciliare le necessità di governo dei processi, con le situazioni e le aspettative degli uomini; 3.3. carichi di lavoro, dimensionamento, organici ― riutilizzando gli stessi volumi rilevati, sono ricalcolati i carichi di lavoro in capo ai processi ed ai nuovi ruoli-posizioni organizzative e, quindi, le risorse virtuali; sono poi identificati tutti gli organici da assegnare alle nuove unità organizzative; 3.4. recuperi ― sono calcolati i recuperi in termini di risorse paragonando la situazione che si propone (to be) con quella in essere (as is); tali recuperi vengono tradotti in costi annuali e proiettati in un triennio; si confrontano poi i costi previsti per l’attuazione del progetto con i recuperi e si verifica dove si pone il punto d’equilibrio (break-even point). Il BPR è una metodologia che ha come scopo l’ottenimento di un gap competitivo per l’Organizzazione oggetto dell’intervento favorevole rispetto ai competitors. Ciò è ottenuto attraverso un riorientamento di tutti i processi dell’Organizzazione al business. Quando citiamo la parola business, intendiamo, di fatto, qualsiasi obiettivo istituzionale che è contemplato nelle strategie dell’Organizzazione. Obiettivo del BPR sono i processi core ovvero quelli fondamentali per il business. Naturalmente questi sono sempre supportati da altri processi identificati come di supporto.
Il BPR è un approccio radicale, poco incline ai compromessi, dove la divisione dei processi in core e non core serve a focalizzare l’organizzazione sugli obiettivi fondamentali, il business per l’appunto. Qualsiasi processo non strettamente collegato al business può, in teoria, essere dimesso, riorientato o terziarizzato. Cade, quindi, nel BPR puro la suddivisione di Porter in processi strategici, operativi e di supporto per lasciare il posto a quella più netta e definita di core e non core (fig. A35). Una volta effettuata tale suddivisione, è importante comprendere, a fondo, il modello e gli obiettivi di business come sono visti dall’alta direzione e se questa intenda effettuare un BPR su tutta l’organizzazione o su alcune aree e quindi definire il dominio dell’intervento. Gli obiettivi nel BPR non possono essere accettati così come sono stati pensati dall’alta direzione dell’Organizzazione, ma devono essere discussi alla luce del gap che competitivo che l’intervento deve assicurare. Concordati gli obiettivi, si classificano i macroprocessi, appartenenti al dominio d’intervento, in core e non core, e si suddividono in aree logiche d’appartenenza o, più semplicemente, si segmenta il business e s’individuano per ogni segmento le filiere dei processi. Per un classico intervento di riprogettazione dei processi gli obiettivi da perseguire sono l’efficacia, l’efficienza, la qualità, per un progetto di BPR il fine è il business ed il gap da conseguire. Il BPR quindi si pone come obiettivi (fig. A36): la massificazione dei ricavi, la drastica riduzione dei costi di regime, l’innovazione di processo, la tecnologia profittevole.
Significa anche rivedere gli investimenti che l’Organizzazione effettua in termini di ricerca, innovazione e sviluppo. Acquisire, vendere, produrre, fidelizzare sono le aree dove il BPR deve intervenire. I processi non devono solo essere efficaci ed efficienti e fornire prodotti di qualità ma funzionare come una squadra dove ogni attore gioca, al tempo stesso, i ruoli di cliente e fornitore all’interno d’una filiera che vede come obiettivo finale comune il cliente esterno, che è l’unico che può assicurare la sopravvivenza dell’Organizzazione. E’ possibile costatare che l’approccio classico di riprogettazione dei processi è limitato ad una visione parziale, il BPR ha bisogno di una visione più allargata dove si opera sui singoli processi tenendo sotto costante controllo l’orizzonte del business.
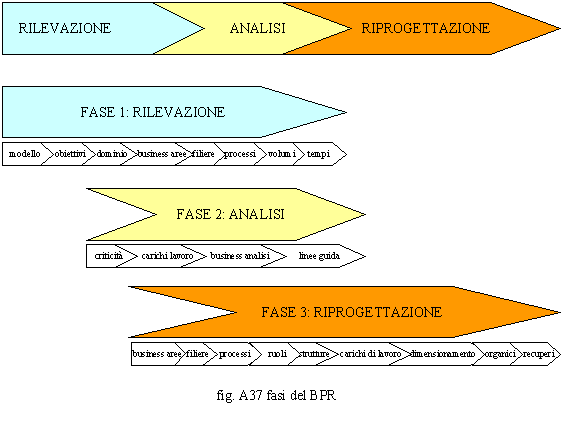
1.1. modello di business ed obiettivi — questa fase è fondamentale; occorre capire bene il funzionamento dell’attuale modello di business e gli obiettivi che si pone il management con un BPR (perché vuole un intervento di BPR e cosa si aspetta da questo); è necessario far comprendere al top management dell’Organizzazione le diversità che esistono fra un BPR ed una classica riprogettazione dei processi, dati i rischi che comporta tale progetto se non è appoggiato con la giusta autorità da tutto il management dell’Organizzazione. 1.2. dominio — è essenziale, prima di operare, rendersi conto del dominio dell’intervento; occorre capirne i confini poiché, essendo questo piuttosto complesso, per ogni processo occorrono tempi di rilevazione e di riprogettazione considerevoli, un errore di valutazione sulla sua estensione, può compromettere i tempi progettuali e renderlo inefficace o tardivo, sempre che non abortisca prima per sfiducia del committente; 1.3. Business Area e filiera dei processi — un intervento di BPR non deve essere condizionato dalle strutture ma deve seguire il business partendo dal livello strategico per poi ricomporlo a livello operativo; per tale motivo si segmenta il business in aree e s’individua, per ognuna di queste, un insieme di macroprocessi o processi di frontiera che saranno il punto di aggancio delle filiere di sottoprocessi; comprendere e documentare le filiere dei processi è fondamentale per comprendere i collegamenti esistenti fra business ed attività dell’Organizzazione 1.4. processi — saranno disegnati, per singola filiera di business, tutti i processi facenti parte del dominio d’intervento; per ogni processo sarà disegnato il flusso e sarà definito il chi fa cosa all’interno dello stesso, assegnando ruoli e posizioni organizzative alle attività componenti; 1.5. volumi e tempi — dovranno essere rilevati, per periodi significativi, i volumi lavorati per processo e poi occorrerà distribuire gli stessi in capo alle attività tenendo conto delle frequenze d’accadimento dei singoli rami componenti i processi (vedi il paragrafo specifico relativo alla valutazione dei processi); dovranno inoltre essere rilevati per ogni attività componente il singolo processo, i tempi standard unitari; questi possono essere calcolati o tramite misurazioni o attraverso medie di tempi dichiarati; ciò è fondamentale per il successivo calcolo dei carichi di lavoro.
2.1. criticità e punti di forza — a questo punto, sarà necessario tirare le somme in termini di punti di forza e di punti di debolezza; l’analisi terrà conto soprattutto dell’aderenza al modello di business dei processi, dell’efficacia, dell’efficienza, della qualità e soprattutto dell’integrazione di ognuno di essi con gli altri, ma porrà la giusta attenzione anche alle sensazioni trasmesse dagli intervistati all’intervistatore, in particolare sui malfunzionamenti segnalati, sul clima aziendale, sullo stile del management, sui conflitti, sulle situazioni di stallo, sul livello di comunicazione, sul livello di formazione, sulle necessità strumentali e formative; 2.2. carichi di lavoro e dimensionamento — avendo a disposizione i tempi standard ed i volumi rilevati dalla fase precedente è possibile calcolare ed analizzare per ogni Processo-ruolo-posizione organizzativa i carichi di lavoro (Carico di lavoro = ∑ tempi standard * volumi lavorati), riportarli in capo ad un periodo annuale, tradurli quindi in termini di risorse virtuali (Risorse virtuali = Carichi di lavoro annui / tempo netto disponibile) e stimare se, nella situazione in essere (as is) sia presente una situazione d’eccesso o di carenza di risorse; 2.3. business analisi — in tale fase si confronta, se possibile, il modello di business dell’Organizzazione con altri presenti sul mercato e si cercano soluzioni applicabili nel breve periodo (solution packeges) per snellire, automatizzare, informatizzare ed in ogni caso modificare il più radicalmente possibile i processi in essere; 2.4. linee guida — poiché gli interventi sui processi richiedono tempi lunghi specie nel caso di un BPR è fondamentale dare un’anticipazione dei risultati in modo che l’Organizzazione possa intervenire prima della conclusione del progetto; per evitare che le soluzioni però siano difformi da quella finale si redigono delle linee guida che servono proprio a dare un indirizzo alle azioni correttive ritenute più urgenti;
3.1. Business aree e filiere di processi — come prima attività, si riprogettano le Aree di business e le filiere dei processi; 3.2. processi ― successivamente si riprogettano i processi ed in questo caso secondo le logiche ed i principi del BPR; ciò può avvenire in modo soft o radicale, nel primo caso parleremo di reengineering, nel secondo di improvement dei processi; si riprogettano quindi le cose che si fanno, il come vengono fatte, il chi le fa e la rete di relazioni che lega tutte le attività nell’ambito di un processo; 3.3. ruoli, posizioni organizzative e strutture ― una volta riprogettati i processi, si definiscono i ruoli-posizioni organizzative (activity owners) responsabili delle attività e le strutture organizzative responsabili dei processi (process owners), attraverso una rigorosa procedura di assegnazione dei processi alle strutture (process allocation); si creano quindi le strutture di coordinamento di livello superiore (centri di responsabilità); si cerca, infine, di conciliare le necessità di governo dei processi, con le situazioni e le aspettative degli uomini; 3.4. carichi di lavoro, dimensionamento, organici ― riutilizzando gli stessi volumi rilevati, sono ricalcolati i carichi di lavoro in capo ai processi ed ai nuovi ruoli-posizioni organizzative e, quindi, le risorse virtuali; sono poi identificati tutti gli organici da assegnare alle nuove unità organizzative; 3.5. recuperi ― sono calcolati i recuperi in termini di risorse paragonando la situazione che si propone (to be) con quella in essere (as is); tali recuperi vengono tradotti in costi annuali e proiettati in un triennio; si confrontano poi i costi previsti per l’attuazione del progetto con i recuperi e si verifica dove si pone il punto d’equilibrio (break-even point). Come abbiamo visto il BPR, prima di essere una metodologia, è uno stato mentale proteso verso il business che viene trasmesso a tutta l’Organizzazione, una continua ricerca di gap e cambi tanto repentini quanto traumatici. Naturalmente, nella realtà tutto deve essere mediato e quindi spesso si assiste ad interventi di riprogettazione classica dei processi spacciati per BPR. Un Business Process Improvement può sembrare più vicino ad un approccio classico ma in effetti si differisce da questo perché è diversa l’impostazione iniziale e le fasi progettuali anche se poi gli interventi sono molto più morbidi (soft) rispetto al BPR. Un intervento di BPR è
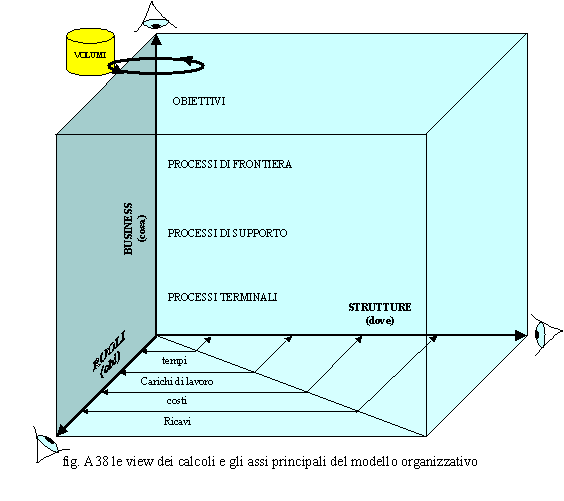
rischioso perché: o il responsabile del progetto deve essere una persona molto esperta, un manager con una visione molto ampia ed un forte skill professionale, che sa coinvolgere tutti e guidarli al successo dello stesso; o l’alta direzione deve essere uno sponsor forte e determinato; o il numero di variabili da gestire è molto elevato; o non si ha sempre la giusta visibilità sugli elementi che inseriti nel sistema possono elevare il gap; o non è sempre vissuto favorevolmente dai managers intermedi e dal personale operativo che vedono minacciate le loro posizioni; o tutte le risorse che operano sul progetto devono essere molto qualificate; o il gruppo di progetto deve essere affiatato e deve possedere, nel suo complesso, un notevole mix di conoscenze, manageriali, organizzative, funzionali e tecnologiche; ma i vantaggi per l’Organizzazione possono essere notevoli. Non siamo ancora di fronte ad un approccio olistico ma questo sicuramente è un passo fondamentale verso tale strada. Un altro problema riguarda il riuso dei processi che, in ambiti diversi, possono assumere attributi differenti. Un processo può, infatti, essere svolto in un certo ambito da certe posizioni organizzative, in un altro da altre con tempi di lavorazione anche differenti. Vediamo di affrontare il problema della valutazione dei processi considerando cosa occorre e quali risultati s’intendono ottenere. In fig. A38 sono rappresentate, attraverso tre assi, le tre viste principali dell’Organizzazione: il business, le strutture, le posizioni organizzative. La vista del business è quella che rappresenta gli obiettivi e, attraverso i processi nelle loro diverse categorie (processi di frontiera, processi di supporto, processi terminali), il come raggiungerli: “cosa fa chi dove”. La vista delle strutture è quella classica normativa : “dove chi fa cosa”. Quella delle posizioni organizzative coincide, invece, con il mansionario: “Chi dove fa cosa”. Queste tre viste non sono importanti solo dal punto di vista normativo ma anche per quello che riguarda le performance del modello organizzativo. Essendo, infatti, presenti in capo ad i processi i dati inerenti le risorse, i tempi di lavorazione, i costi ed i ricavi è infatti possibile valutare i carichi di lavoro ed i margini degli stessi. Se poi tali dati si propagano, sommandoli, sui tre assi, rappresentati in fig. A38, è possibile ricavare i tempi, i carichi di lavoro, i costi, i ricavi diretti ed i margini a livello di: o
aree di business ed obiettivi o
processi e sottoprocessi o
strutture ed unità organizzative o ruoli e posizioni organizzative. E’ difficile reperire i volumi a livello terminale; è più facile che tali dati si reperiscano a livello di macroprocesso o di processo intermedio.
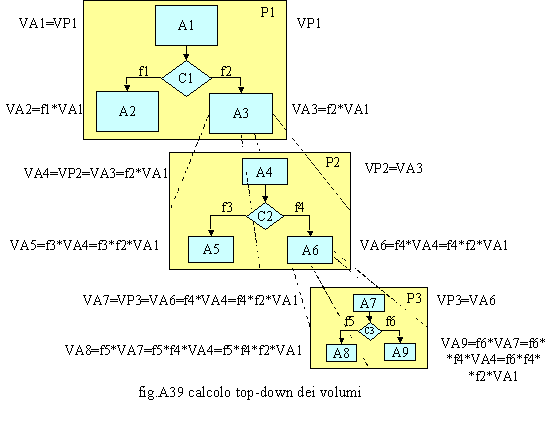
In questa ed in quelle a
seguire inerenti il trattamento dei volumi, si identifica con: o VPi = volumi del processo i-mo o VAi = volumi dell’attività i-ma (per semplicità i sottoprocessi terminali o di supporto sono stati considerati attività o Ci = condizione i-ma o fì = frequenza di accadimento i-ma (ovvero la probabilità che il processo continui su un determinato ramo uscente da una condizione Cj ), questa viene data in termini di valore percentuale. Dall’esempio riportato in fig. A39, procedendo dall’alto in basso (top down) si osserva che l’attività A1 sarà svolta sempre (100%), per cui i suoi volumi coincidono con quelli del processo P1 (VA1=VP1). I volumi dell’attività A2, invece, sono pari ad i volumi del processo P1 ponderati per la probabilità d’esecuzione del ramo dove tale attività è presente (VA2=f1*VP1=f1*VA1). Utilizzando lo stesso criterio, i volumi dell’attività A3 saranno ponderati per la frequenza f3 (VA3=f2*VA1). Considerando che l’Attività A3 è esplosa nel processo P2 che è rappresentativo della stessa, si ottiene che: A3=P2 e quindi VP2=VA3=f2*VA1. Proseguendo, applicando lo stesso metodo si ottiene che: VA5=f3*f2*VA1 e VA6 =f4*f2*VA1. Come è possibile notare con tale metodo è possibile propagare i volumi dall’alto in basso (top down). Moltiplicando gli stessi per i tempi, i costi, i ricavi, aggregando in capo al processo i dati e reiterando tale procedimento dal basso verso l’alto (bottom up), percorrendo in tal verso l’intera filiera è possibile ottenere, a livello di processo di frontiera i totali di tempi (Σ tempi*volumi), carichi di lavoro (Σ tempi*volumi*numero di risorse), costi (Σ costi*volumi), ricavi (Σ ricavi*volumi), e margini (Σ ricavi*volumi -Σ costi*volumi). E’ possibile, utilizzando la stessa procedura, ottenere l’equivalente in capo alle strutture ed ai ruoli come rappresentato in fig. A38. In fig.A40 è riportata la procedura d’aggregazione bottom up dei volumi. Con lo stesso procedimento, come dimostrato nel periodo precedente, è possibile aggregare i tempi (Σ tempi*volumi), i carichi di lavoro (Σ tempi*volumi*numero di risorse), i costi (Σ costi*volumi), i ricavi (Σ ricavi*volumi), ed i margini (Σ ricavi*volumi -Σ costi*volumi). Tale procedura è utilizzata quando i volumi sono noti a livello terminale. Poiché in realtà, i volumi possono trovarsi a qualsiasi livello si usano contemporaneamente ambedue le tecniche per valorizzare i volumi in capo a tutte le attività e poi si procede ad aggregare tempi, costi e ricavi ed a calcolare i carichi di lavoro ed i margini. Naturalmente i ricavi si riferiscono sempre a quelli diretti e quindi imputabili ad i processi ed alle attività. E’ importante notare che (fig. A39) VA2+VA3=f1*VA1+f2*VA1=(f1+f2)*VA1=VA1 essendo f1+f2=1 cioè al 100% dei volumi. Di qui si ricava un principio generale: la somma dei volumi uscenti da una condizione coincide sempre con i volumi che sono presenti in ingresso alla condizione stessa. Quando quindi si rilevano
i volumi e questi sono a livello basso e si aggregano verso l’alto occorre,
mano a mano che si procede verso l’alto verificare che tale condizione sia
rispettata, se ciò non avviene possono essere intervenute le seguenti
condizioni: o esistono delle code che generano le squadrature; o le frequenze del modello, presenti sulla condizione, ove è stata riscontrata la squadratura sono errate; o esistono dei ricicli sul processo (loop) che incrementano i volumi in input alla condizione ed i volumi di tale fenomeno aggiuntivo non sono stati rilevati in modo omogeneo in input ed in output; o sono stati dichiarati dei dati errati.
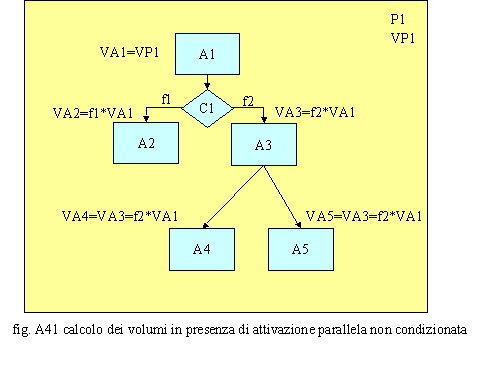
Spesso capita che da un’attività se ne attivino altre in parallelo (fig. A41). Ciò succede, ad esempio, quando s’inviano più copie di uno stesso documento o di un e-mail ad altrettanti attori che si attiveranno contemporaneamente. In tale caso i volumi coincidono con quelli dell’attività che ha sollecitato la parallelizzazione: V4=VA5=VA3. Quando entrano in input ad un’attività più rami contemporaneamente, ci troviamo di fronte ad una situazione di ambiguità. Occorre, infatti, sapere se l’attività, per essere eseguita, deve attendere che pervengano i volumi di tutti i rami (condizione “AND” della logica booleana) o occorre lavorare i volumi d’ogni ramo mano a mano che questi si presentano (condizione di “OR” della logica booleana).
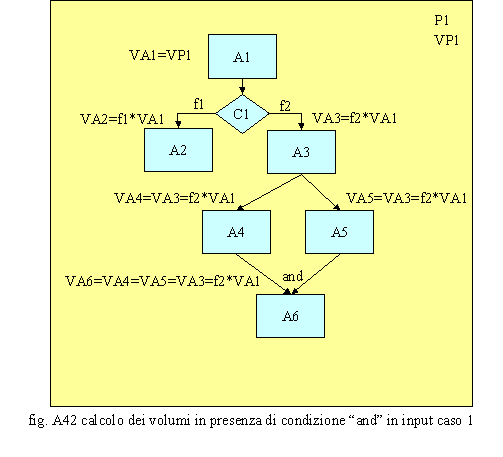
In fig A42 è rappresentata una condizione di AND; in questo caso il volume dell’attività A6 è uguale a quello di A4 ed a quello di A5. E’ la classica situazione in cui si invia copia di un documento per due pareri di merito, una volta pervenuti gli stessi, si attende finché non giungono ambedue, si accoppiano e si archiviano con un unico atto lavorativo.
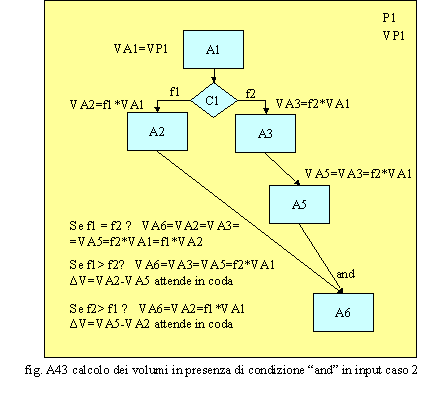
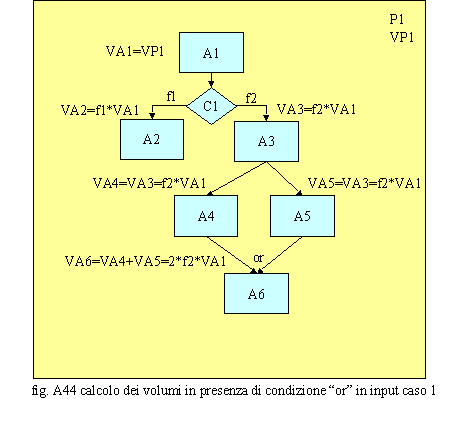
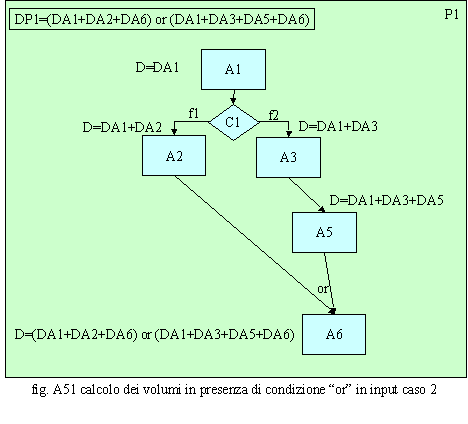
Nel caso della fig. A43, invece, è più complesso calcolare gli effetti indotti sui volumi dal nodo di AND in quanto questi, in ingresso all’attività A6, non sono uguali e quindi non sono accoppiabili in modo sincronizzato. In effetti, tale situazione non dovrebbe esistere poiché, a monte della ricongiunzione dei rami, vi è una condizione (C1) che è, a tutti gli effetti, un nodo di OR e quindi a valle di questo sarebbe più logico che esistesse una condizione di OR oppure una condizione di AND con in ingresso volumi uguali e quindi accoppiabili. Un AND, a valle di una condizione di OR, potrebbe non trovare significato; non è chiaro, infatti, nella dinamica continua degli eventi, quando la condizione di AND è soddisfatta poiché gli oggetti selezionati dalla condizione C1 sono diversi e quindi non ci troviamo di fronte ad un caso accoppiamento o quanto meno mancano le regole per poterlo effettuare. In tale caso la condizione di AND deve scattare ogni qualvolta un volume di un ramo s’incrocia con uno qualsiasi di un altro ramo in ingresso all’attività A6 i cui volumi, quindi, sono pari ai volumi minori che sono generati dalla condizione C1. Quelli rimanenti, non potendo essere accoppiati, rimarrebbero in coda all’attività A6 fino all’arrivo d’altri volumi accoppiabili. Infatti, l’attività A6 è costretta ad interrompersi quando i volumi minori sono finiti e ad accumulare i volumi residui poiché non riesce più ad accoppiarli e quindi a risolvere la condizione di AND. Se il nodo di AND conoscesse le regole di accoppiamento degli oggetti (regole tipo: ad ogni tipo a accoppia 2 tipo b, oppure ogni n tipo a, aventi codice di accoppiamento c, accoppia un tipo b sempre con codice di accoppiamento c) sarebbe possibile accoppiare combinazioni di oggetti di un ramo con combinazioni di un altro anche attraverso un codice identificativo d’accoppiamento. Per esempio, la prima regola, citata tra parentesi, consentirebbe di accoppiare per ogni bullone che ha avuto bisogno di un’attività di trattamento A2 due dadi che sono stati lavorati con le attività A3 ed A5. La seconda regola permetterebbe, in un magazzino, d’accoppiare i componenti di un apparato, identificati dal codice di richiesta, con la bolla d’accompagnamento, identificata dallo stesso codice. Il caso riportato in fig. A44 rappresenta una situazione in cui i volumi in input all’attività A3 si raddoppiano, per divisione dei flussi, in output. In input all’attività A6 arriverà quindi il doppio dei volumi che non hanno alcun bisogno di sincronizzarsi poiché questi confluiscono su tale attività secondo un meccanismo di OR. L’attività A6 quindi tratterà il doppio dei volumi rispetto alla attività A3: VA6=VA4+VA5=2*f2*VA1.
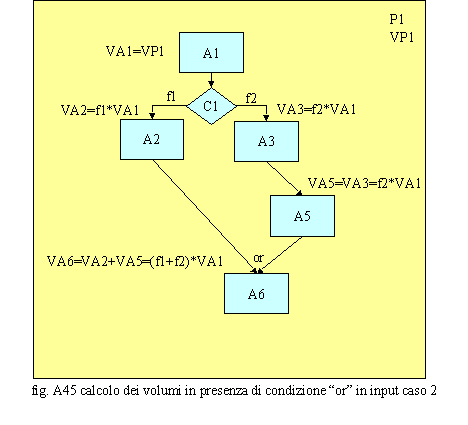
In fig.A45 è riportato un caso in cui due flussi processuali di volumi si ricongiungono, a valle su di un’attività A6, a fronte di una condizione C1, a monte. In questo caso i volumi dell’attività A6 sono dati dalla sommatoria dei flussi in input: VA6=VA2+VA5=(f1+f2)*VA1. Se infatti i volumi sono significativi per calcolare costi, ricavi, tempi lavorativi e carichi di lavoro e quindi incidono sull’efficienza del processo, le durate sono significative sia per l’efficienza, più dura un processo più consuma energia, sia sull’efficacia, meno dura un processo più è alto il livello di servizio. A seguire sono riportati una serie d’esempi che evidenziano situazioni significative per il calcolo delle durate.
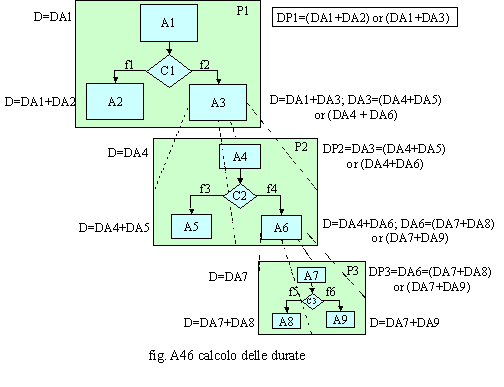
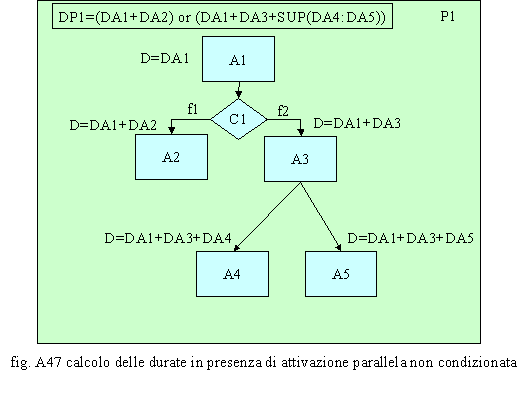
La durata del processo P1 può essere data dalla sommatoria delle durate delle attività concatenate nella sequenza A1→A2 oppure nella sequenza A1→A3, in funzione della condizione C1. A sua volta, l’attività A3 coincide con il sottoprocesso P2 e quindi la durata di questa sarà data dalla sommatoria delle durate delle attività concatenate nella sequenza A4→A5 oppure nella sequenza A4→A6, in funzione della condizione C2. Infine coincidendo l’attività A6 con il sottoprocesso P3 la durata di questa sarà data, a sua volta, dalla sommatoria delle durate delle attività concatenate nella sequenza A7→A8 oppure nella sequenza A7→A9, in funzione della condizione C3. È importante notare come le durate vadano calcolate in funzione dei possibili percorsi. Se quindi considerassimo tutti i percorsi possibili, potremmo valutare i più brevi, quelli più lunghi nonché calcolare una durata media unitaria ed una durata media ponderata in funzione delle frequenze d’accadimento. Ambedue gli ultimi aspetti sono importanti in quanto forniscono valutazioni diverse ed altrettanto significative sulla durata media. In particolare il secondo, rispetto al primo, considera quanto influiscono i volumi sulla durata. Nel caso riportato in fig. A47, è possibile notare che la durata del processo può essere quella derivante dalla sommatoria delle durate delle attività concatenate nella sequenza A1→A2 oppure quella che deriva dalla sequenza A1→A3→A4 se la durata di A4 è superiore alla durata di A5 o quella che deriva dalla sequenza A1→A3→A5 se la durata di A5 è superiore alla durata di A4.
Il processo, infatti, parallelizza le attività dopo l’attività A3 e quindi si conclude solo dopo che l’attività più lunga fra A4 ed A5 termina.
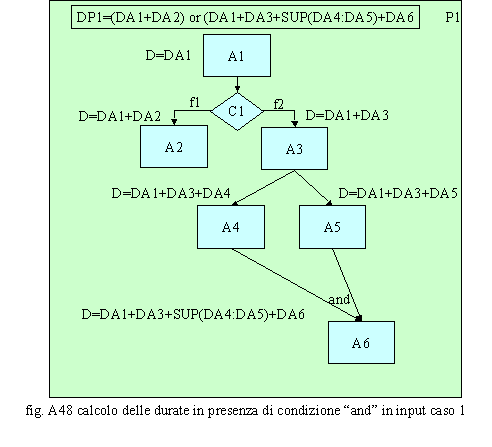
Il caso di fig. A48, derivato dal precedente, ripropone la situazione in cui due flussi si ricongiungono su un’attività attraverso un nodo di AND, avendo a monte una condizione e quindi un nodo di OR. I volumi del processo, potranno essere, a seconda della condizione C1, pari alla sommatoria delle durate presenti sulle attività del percorso A1→A2 oppure pari al valore maggiore fra le sommatorie derivanti dai percorsi A1→A3→A4→A6 ed A1→A3→A5→A6. Può, infatti, succedere che prima di soddisfarla
si verifichino n flussi sul percorso A1→A2 che si arrestano sull’attività
A5, in attesa che sia soddisfatta la condizione AND. Quando finalmente perviene
un flusso sul percorso A1→A3 la condizione viene soddisfatta. Il calcolo
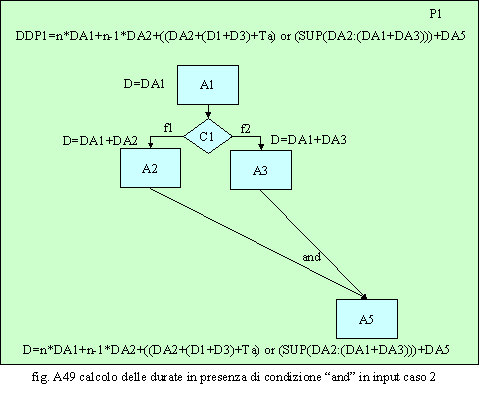
della durata può avvenire nel seguente modo: o gli n flussi sul percorso A1→A2 portano ad una durata pari a n*(DA1+DA2) e ad uno stop del processo in attesa che si verifichi la condizione AND; o se si attiva il flusso sul percorso A1→A3 subito dopo l’ultimo flusso del percorso A1→A2 sono svolte le attività A1 ed A3 in parallelo alla A2 e quindi la durata del processo è pari a n*DA1+n-1*DA2+SUP(DA2:(DA1+DA3))+DA5; o se si attiva il flusso sul percorso A1→A3 quando l’ultimo flusso del percorso A1→A2 ha svolto le attività A1 ed A2 la durata del processo è pari a n*DA1+n*DA2+(DA1+DA3)+ Ta +DA5 dove Ta è il tempo d’attesa fra un flusso d’un tipo e quello d’un altro tipo.
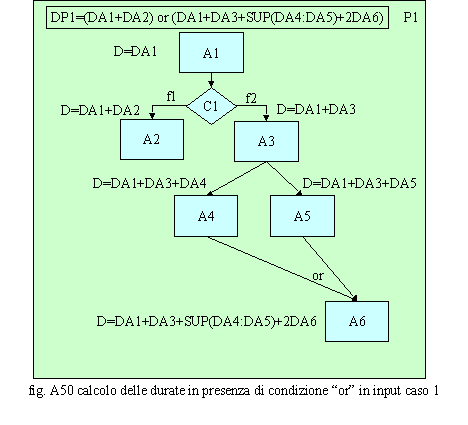
Nel caso riportato in fig. A50 un nodo di OR si trova a valle di due flussi generati, in parallelo, da un’attività a monte. In tale situazione la durata può essere la somma delle durate delle attività presenti sul percorso A1→A2 oppure la somma della durata dell’attivita A1, della A3, di quella maggiore fra le A4 ed A5, poiché queste sono eseguite in parallelo, ed infine della A6.
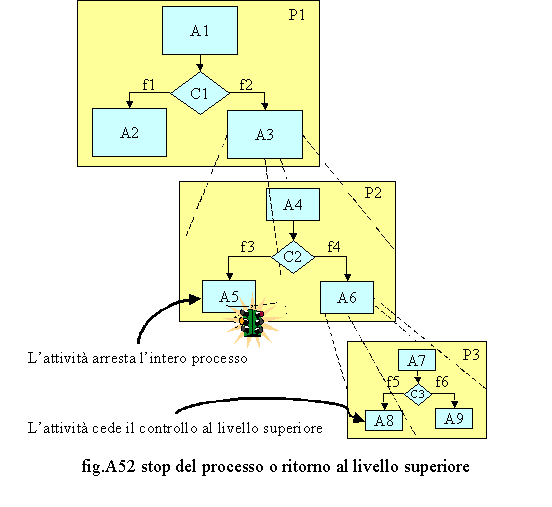
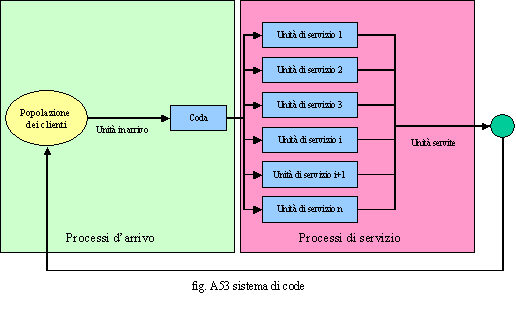
Un altro fattore importante (fig. A52) da considerare nella valutazione dei processi, specie nel caso in cui questi sono nidificati riguarda il fatto che un ramo terminale di un sottoprocesso può ricondurre al processo di livello superiore o interrompere l’intero processo. Per tale motivo, mentre non è importante avere un simbolo di stop per un processo non nidificato, poiché non si crea ambiguità, ciò è necessario in presenza di una filiera di processi e di sottoprocessi. Cenni sulla teoria delle code. Abbiamo anche analizzato come si calcolano le durate. Tutto ciò non è sufficiente. Occorre infatti considerare che tali calcoli servono per avere una visione di massima e statica del processo, mentre questo è dinamico ed i volumi non attivano il processo sempre in modo regolare ma secondo delle distribuzioni probabilistiche. Noi non possiamo sapere in una biglietteria quando e come esattamente arriveranno i passeggeri che intendono imbarcarsi ma possiamo prevederlo in funzione degli orari dei vettori e di dati statistici. Ogni qual volta il tempo intercorrente fra un evento e l’altro è inferiore al tempo d’erogazione del servizio, avremo il formarsi di una coda. Più questa è consistente e maggiore sarà il livello di disservizio percepito dagli utenti del servizio. Occorre precisare che esiste una teoria consolidata sul trattamento delle code e che questa è piuttosto complessa, non essendo il presente scritto un trattato specializzato sull’argomento, daremo solo dei cenni sul trattamento delle stesse. Dalla breve descrizione comprenderemo, in ogni caso, come volumi e durate siano strettamente connessi e come questi influiscono sui livelli di servizio e quindi sulla qualità dei processi. Se rammentiamo che una filiera di processi si compone di un processo di frontiera, n sottoprocessi di supporto ed m sottoprocessi terminali, e consideriamo che ognuno di questi può essere responsabile di una coda e quindi d’un disservizio, ci rendiamo conto della vastità e della complessità del problema e soprattutto del fatto che questo può essere affrontato solo utilizzando dei sistemi di calcolo adeguati per la simulazione in tempo reale delle code. Viceversa, quale compromesso, sarebbe possibile simulare le stesse con dati statistici ed effettuare delle proiezioni sul dimensionamento del servizio. Naturalmente, il fine di tali simulazioni è quello d’eliminare le code, anche se ciò è impossibile, e quindi, nella pratica, si cerca contenere, al minimo, tale situazione di disagio. Proviamo a dare una definizione di coda. Possiamo anche dire che una coda è un sistema composto da un insieme non vuoto d’aree d’attesa (buffer) capaci di accogliere entità clienti che non possono essere serviti immediatamente. I Clienti che non trovano un servitore libero si dispongono naturalmente in modo ordinato cioè in coda. Dal punto di vista dinamico una coda è costituita da due processi stocastici: i processi d’arrivo e quelli di servizio. Gli elementi che
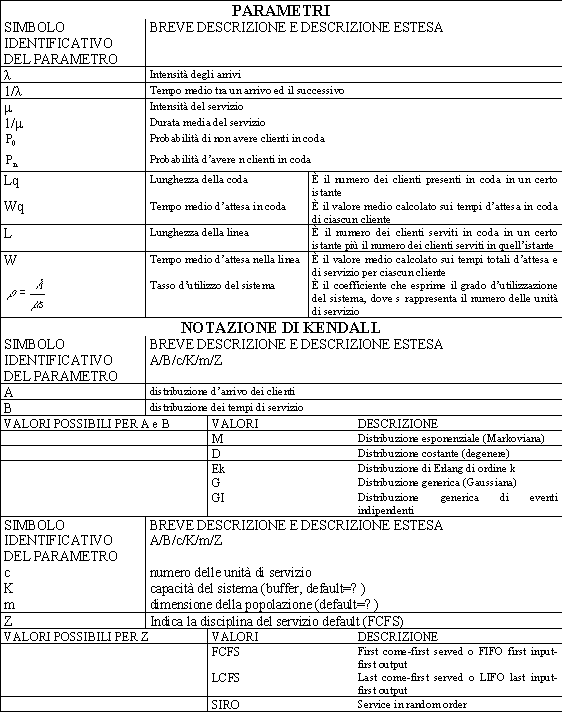
definiscono completamente il fenomeno d’attesa sono quindi: o
la popolazione dei clienti, o
i processi d’arrivo, o
la coda vera e propria, o
le unità di servizio o
i processi di servizio o le norme di servizio. La popolazione rappresenta l’insieme dei potenziali Clienti, ovvero l’insieme da cui questi arrivano e dove tornano dopo essere stati serviti. In genere si distinguono popolazioni diverse in funzione del tipo di servizio che queste richiedono. I processi d’arrivo sono quelli che gestiscono i clienti quando questi si presentano tenendo conto della distribuzione relativa all’intertempo d’arrivo. La coda è un vero e proprio buffer in grado di contenere ed intrattenere i clienti (Aree d’intrattenimento). Le unità di servizio sono entità umane o strumentali in grado d’erogare il servizio, rispettando dei tempi lavorativi unitari stabiliti nei processi di servizio. I processi di servizio sono l’insieme delle attività necessarie a trattare le informazioni, a reperire fra i prodotti/servizi quello o quelli richiesti, a fornirli, a verificare il livello di soddisfazione, a disimpegnarsi per passare al prossimo cliente in coda. Le norme di servizio regolamentano come gestire il cliente, la coda ed erogare il servizio. All’interno di queste esiste quella che viene
definita disciplina di servizio ovvero la modalità di trattare la coda: o
FCFS (first-come
first-served) o FIFO (first-input first-output)
— servizio in ordine d’arrivo; o
LCFS (last-come
last-served) o LIFO (last-input last-Output)
— servizio in ordine inverso d’arrivo; o SIRO (service in random order) — servizio in ordine casuale. Tutti gli elementi di una coda
possono essere evidenziati attraverso le seguenti variabili:
In particolare le
distribuzioni dei tempi d’arrivo A e quella dei tempi di servizio B possono
assumere le seguenti configurazioni: o M: distribuzione esponenziale (Markoviana) o D: distribuzione costante (Degenere) o
Ek: distribuzione Erlang d’ordine k o G: distribuzione generica o GI: distribuzione generica d’eventi indipendenti (per gli arrivi). La coda viene, in genere,
identificata (notazione di Kendall) attraverso una stringa dei suddetti
parametri, che rispetti la sequenza precedentemente citata, ove ogni simbolo,
che rappresenti una variabile sia separato da ”/”. Per esempio M/M/1
equivalente di M/M/1/∞/∞FCFS rappresenta una coda avente intertempi
d’arrivo e tempi di servizio con andamento esponenziale, una sola unità di
servizio, capacità del sistema, dimensione della popolazione e disciplina di
servizio di default (∞,∞,FCFS). Lo stato di un sistema dinamico in un determinato istante temporale rappresenta l’informazione di base per conoscere l’evoluzione futura del sistema stesso, una volta noti i valori del fenomeno stocastico a cui questo è soggetto. Nel caso della coda, il suo stato è dato dal numero di clienti presenti, dal tempo trascorso dall’arrivo dell’ultimo cliente, da un operatore booleano on-off, per ogni unità di servizio, che indichi se questa è attiva o meno, nonché dal tempo trascorso dall’inizio del servizio. Conoscere il funzionamento delle code è
fondamentale per qualsiasi analisi d’efficacia e d’efficienza riguardante i
processi. La teoria delle code individua alcuni indici di
prestazione direttamente legati ai costi ed alle durate dei servizi
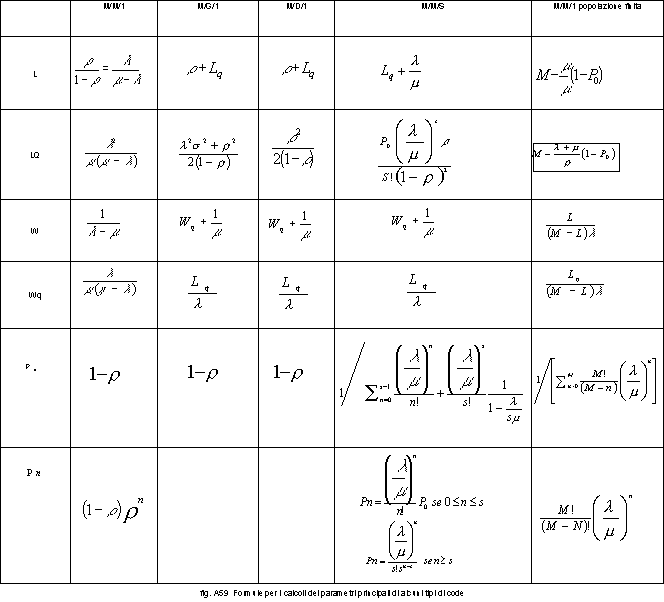
erogati, che, quando valgono alcune ipotesi sono facilmente calcolabili: o Ls: numero medio di clienti nel sistema (sia in attesa che riceventi servizio) o Lq: numero medio di clienti in attesa di servizio o Ws: tempo d’attesa medio dei clienti presenti nel sistema (sia in attesa che riceventi servizio) o Wq: tempo d’attesa medio dei clienti prima d’essere serviti o Pn: probabilità che, a regime, vi siano n clienti presenti nel sistema o
ρ: fattore d’utilizzazione delle unità di servizio
(rapporto fra tempo impiegato in servizio e tempo disponibile complessivo) I valori che possono essere assunti dai predetti indici
dipendono dalla consistenza della coda e dal tasso d’arrivo dei
clienti. Il progettista del sistema di simulazione deve determinare le caratteristiche
della coda, per esempio il numero delle unità di servizio e la loro velocità
di servizio, in modo da soddisfare le specifiche. Chiaramente lo scopo del
progettista deve essere quello di minimizzare i costi fornendo un livello di
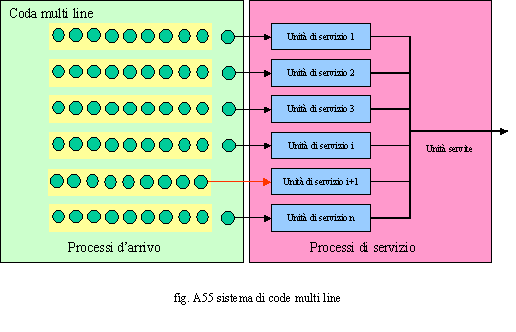
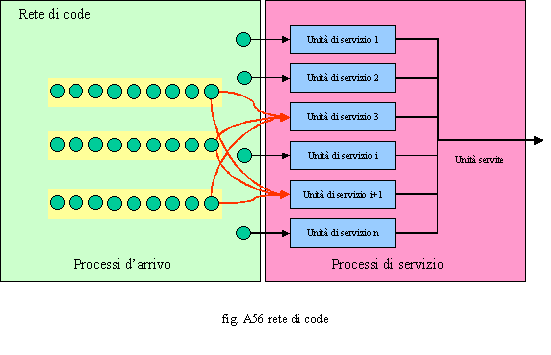
servizio qualitativamente apprezzato dal cliente. E’ possibile rappresentare e simulare vari tipi di code. Quelle più ricorrenti sono la single line, la multi line e la rete di code.
In fig. A55 è rappresentato il funzionamento della coda multiline. In tale situazione i clienti sono divisi in più code ed ogni coda è servita da una linea di servizio.
Per la difficoltà dei calcoli coinvolti la teoria delle code, in generale, fornisce solo modelli descrittivi, ovvero modelli che permettono di valutare le prestazioni del sistema a fronte d’ipotesi sulla sua struttura, ma che non risolvono direttamente problemi di progetto come fanno i modelli normativi. Di conseguenza, il progetto d’una coda, di solito, avviene per tentativi attraverso metodiche che transitano per la progettazione e l’analisi dei diagrammi di flusso. Si formulano delle ipotesi sulla struttura del sistema, si valutano le relative prestazioni, e si sceglie dopo la formulazione e la sperimentazione di varie ipotesi il modello più adeguato. Ciò è quanto va sotto il nome di: what if analysis. La fase di calcolo delle prestazioni avviene attraverso l’utilizzo di formule matematiche chiuse, quando queste sono note, oppure, per sistemi particolarmente complessi che utilizzino più code, attraverso la realizzazione d’esperimenti simulativi o l’utilizzo di metodi approssimati. Nel caso in cui gli istanti d’arrivo dei clienti ed i tempi d’espletamento dei servizi sono noti a priori, è possibile determinare le prestazioni del sistema; se, infatti, la disciplina di servizio è FCFS, per ogni cliente, l’istante d’uscita dal sistema è dato dalla somma del suo tempo di servizio e del massimo tra il suo istante d’arrivo e l’istante d’uscita del cliente precedente. Dati quindi i valori: o
a(i): istante d’arrivo dell’ i-mo cliente o
s(i): durata del servizio del cliente i-mo o
x(i): istante d’uscita dal sistema del cliente i-mo o
w(i): tempo d’attesa del cliente i-mo o
n(i): numero di persone nel sistema all’istante t stabilito che x(0)=0 si ottiene: x(i)=s(i)+max{x(i-1),a(i)};
w(i)=x(i)-s(i)-a(i) con i=1,2,3,…,m. Quindi per calcolare il numero dei clienti presenti nel sistema all’istante t, è sufficiente contare il numero di clienti i per cui a(i)≤t<x(i), dal momento che un cliente è nel sistema nell’istante in cui entra mentre non vi è più nel momento in cui esce. Nei casi pratici, si possono trovare code con intertempi d’arrivo dei clienti e tempi di servizio soggetti a distribuzioni probabilistiche di qualunque tipo. Quella che trova maggiore applicazione è quella esponenziale. Va detto che una variabile aleatoria x ha una distribuzione esponenziale con λ>0 quando la sua densità p(x) è:
Si ricorda che: o
una variabile aleatoria discreta X è un’entità che può
assumere un numero discreto (finito o infinito) di valori xi; ogni valore xi ha
probabilità d’occorrenza P(X=xi)=pi, dove
o
una variabile aleatoria continua X è un’entità che può
assumere valori x in un sottoinsieme s della retta reale composto da uno o più
intervalli; ogni intervallo infinitesimo d’ampiezza dx ha probabilità
I tempi intercorrenti fra due eventi successivi, relativi
allo stesso processo, possono essere modellati per tramite di una variabile
aleatoria esponenziale, se soddisfano le seguenti condizioni: o la probabilità che un evento si manifesti in un intervallo di tempo infinitesimo dx è proporzionale a dx con λ come costante di proporzionalità: P(x<X≤x+dx)= λdx; o la probabilità che un evento si manifesti in un intervallo di tempo infinitesimale dx è nulla; o la probabilità che l’evento successivo ritardi oltre un dato limite non dipende da quanto tempo è avvenuto l’evento precedente. Dalla densità possiamo ricavare la funzione di distribuzione cumulativa o Probabilità della distribuzione (fig. A57): se
Un altro tipo di distribuzione (fig. A58) che viene utilizzata, quando gli intertempi sono esponenziali, è quella di Poisson che presenta la seguente funzione di distribuzione delle probabilità:
Il processo di Poisson
N(t) ha valore atteso
Cercheremo ora di dare una visione d’insieme sulle distribuzioni più utilizzate e sui parametri di valutazione relativi alle stesse. Per fare ciò abbiamo bisogno di fornire delle definizioni che riportiamo nelle tabelle a seguire. Alcune di queste sono ornmai note, in quanto descritte in precedenza.
Nella tabella riportata di seguito, sono evidenziate, per le code più significative ed in genere più utilizzate, le formule per il calcolo dei parametri più importanti.
Se a questo si aggiunge che per avere una visione completa occorre valutare le performance di periodo (statiche) e simulare cosa può succedere a fronte di una certa frequenza d’accadimento degli eventi e di una certa distribuzione dei volumi in input (simulazione del comportamento dinamico), è facile comprendere come e perché molte organizzazioni scelgano di operare sulle strutture piuttosto che sui processi. Concezione, in ogni caso errata, poiché, operando sulle strutture, non si risolvono i problemi insiti nei processi, ma si delega la soluzione degli stessi ai responsabili e, se questa richiede degli investimenti, poiché la decisione spetta all’imprenditore od al top management, si ottiene come risultato che i responsabili di struttura, più motivati, si livellano al massimo dell’efficacia e dell’efficienza raggiungibile, nell’ambito dei propri poteri e quindi della propria autonomia. In tal modo si rischia di perdere opportunità serie per mutare ed evolversi, nonchè la possibilità di trasformare i problemi in occasioni di riflessione e di trasformazione. I processi sono complessi ma, prima o poi, occorre affrontarli, per far sì che l’Organizzazione risolva i suoi problemi reali che sono e saranno sempre legati al fare piuttosto che al governare. In fig. A60 sono evidenziate le tappe percorse, nel tempo dalla qualità. |
|
|
|